| Molecular Basis of Inheritance Refresher Course |
| Molecular Basis of Inheritance Concepts Files |
| Molecular Basis of Inheritance Master Files |
| Molecular Basis of Inheritance Revision Note |
| Molecular Basis of Inheritance Note 1 |
| Molecular Basis of Inheritance Reference Book |
Molecular Basis of Inheritance
Table of Content
- DNA
- Definition of DNA
- Search of Genetic Material
- RNA World
- What is DNA Replication?
- Definition of Transcription
- Definition of Genetic Code
- Definition of Genetic Code Table
- Definition of Translation
- Frequently Asked Question (FAQs)
We are aware of the concepts of Inheritance, its pattern and genetic basis. As we know that the genetic basis resides in nucleic acid found in living beings. There are two types of nucleic acids:
- Deoxyribonucleic Acid (DNA)
- Ribonucleic Acid (RNA)
In living organisms, DNA act as the genetic material and RNA act as genetic material in some viruses, and play the role of messenger. DNA is located in nucleus primarily, and is also found in cell structures called mitochondria.
DNA
DNA was first isolated by Friedrich Miescher in the year 1869 and Francis Crick and James Watson identified its molecular structure in 1953.
Definition of DNA
“Deoxyribonucleic acid is a molecule that carries the genetic instructions used in growth, development, functioning and reproduction of all known Living Organisms and many viruses.” It is a long polymer of deoxyribonucleotides and length of DNA depends on the number of nucleotides present in it. Most DNA molecule has two biopolymer strands coiled around each other to form double helix. These two DNA strands are termed as polynucleotides as they are composed of simple monomer units, that is. nucleotides.
Each nucleotide is composed of one of 4 nitrogen – containing nucleobases (such as cytosine (C), adenine (A), guanine (G) and thymine (T)), a phosphate group and a sugar called deoxyribose. These nucleotides are connected via covalent bond forming a chain between sugar of one nucleotide and the phosphate of the next, thereby resulting in an alternating sugar – phosphate backbone.
Following figure shows the double helical structure of DNA with sugar – Phosphate backbone:
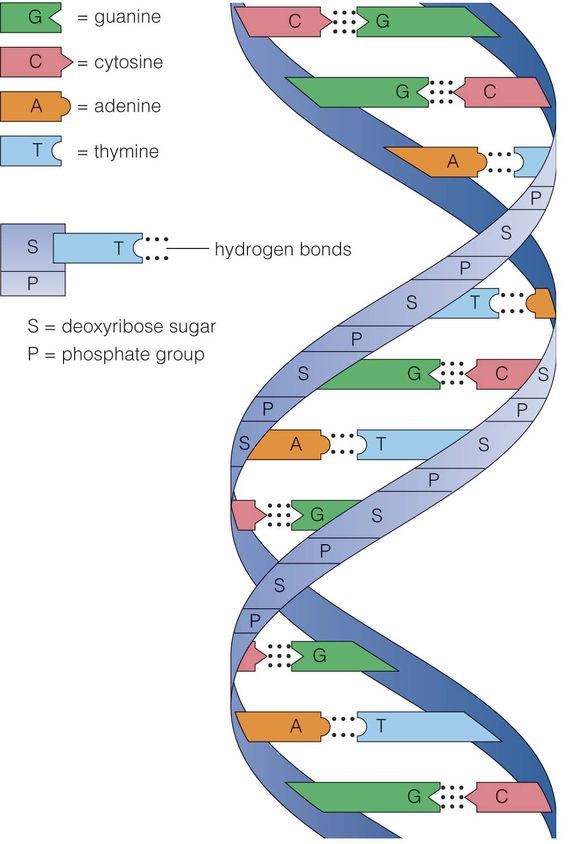
shows the double helical structure of DNA with sugar – phosphate backbone[/caption]DNA consists of biological information and its backbone are resistant to cleavage. Both the strands of DNA store same biological information and this information gets replicated when the two strands get separated. These two strands run in opposite direction and are antiparallel to each other.
Salient features of double helical structure of DNA
- DNA is composed of 2 polynucleotide chains and its backbone constitutes of sugar – phosphate and the bases project inside.
- Both the strands of DNA possess anti – parallel polarity. It implies, if the polarity of one strand is 5’à3’ then the other strand will be 3’à5’.
- The bases in strands are paired via hydrogen bond (H – bond). It is important to note that Adenine forms two hydrogen bonds with Thymine from opposite strand and vice – versa. In the same way, Guanine bonds with cytosine with 3H – bond. As a result, always purine comes opposite to a pyrimidine.
- The two strands or chain are coiled in right – handed fashion and the pitch of helix is 3.4nm and there are around 10 bp in each turn. Thus, the distance between a bp in a helix is around 0.34 nm.
- The plane of one base pair stacks over another in double helix and this in addition to H – bond results in the stability of the helical structure.
- The double helical structure has major and minor grooves along the phosphodiester backbone.
- The genetic information resides on one of the two strands called sense strand or template strand.
- H – Bond is formed between purine and pyrimidine only. The one base arrangement possible in the structure of DNA are A – T, T – A, G – C and C – G.
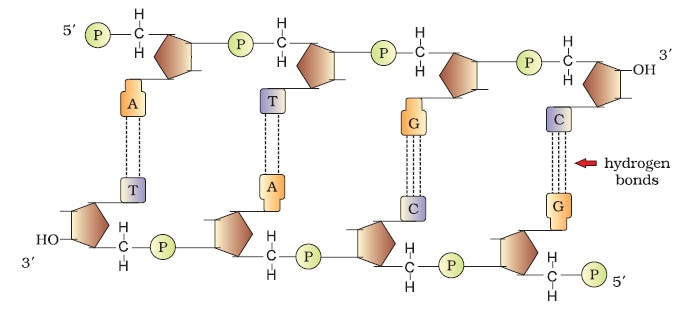
Following figure shows the double stranded polynucleotide chain with all the features as discussed above, that is. 2 polynucleotide chains, its backbone with sugar – phosphate bond and its base arrangement (A – T, T – A, G – C and C – G)
“Each chromosome consists of one continuous thread – like molecule of DNA coiled tightly around proteins, and contains a portion of the 6,400,000,000 base pairs (DNA building blocks) that make up your DNA.” The manner in which DNA is packaged into chromatin is the factor that control the production of protein.
Packaging of DNA Helix
- Packaging in Prokaryotes – In prokaryotes well – defined nucleus is not present absent and therefore, DNA is held together with some proteins in a region called nucleoid. Here, the DNA is organized in the form of large loops held by proteins.
- Packaging in Eukaryotes – The organization of DNA is complex in eukaryotes. In the year 1974, Reger Kornberg reported that chromosome is composed of protein and DNA. On the basis of presence of amino acid residue with charged side chains, a protein gains its charge. Histones are the proteins that are rich in arginine and lysine residues. Both these amino acids carry positively charged and organize themselves to make a unit of 8 molecules referred as Histone Octamer. The negatively charged DNA is wrapped around positively charged Histone Octamer to form the structure called nucleosome.
Following figure shows the structure of nucleosome. It is made up of four types of proteins – H2A, H2B, H3 and H4 occurring in pairs.
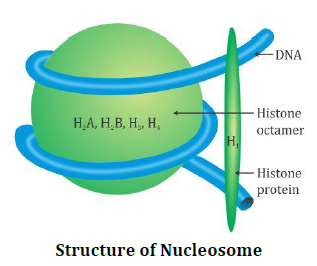
Structure of Nucleosome[/caption]One nucleosome comprise of 200 base pair of DNA helix and these are repeating units of chromatin which are thread like colored bodies in nucleus. When observed under electron microscope, it appears as “beads on string.”
Non – Histone Chromosomal Proteins
These are additional set of proteins which contribute to the packaging of chromatin at higher level. Following regions are present in chromatin –
- Euchromatin – It is loosely packed in a typical nucleus. It is transcriptionally active.
- Heterochromatin – These are densely packed and are stains dark. It is transcriptionally inactive.
Search of Genetic Material
Transforming Principle – It was an early name for DNA. In the year 1928, scientists were not aware that DNA carried genetic information but they were aware that there was something that causes bacteria to transform from one form to another.
Frederick Griffith in the year 1928 carried out an experiment on pneumococcus bacteria. These bacteria were of two types, that is. smooth type(S) and rough type (R). When Streptococcus pneumoniae bacteria were grown on a culture plate, some produced rough colonies while some produced smooth shiny colonies. This is so because the S strain bacteria consist of polysaccharide (mucous) coat, while R was not having any coat. When a mouse was infected with S strain, they died due to pneumonia infection but mice infected with R strain do not developed any infection (Please refer the image below). Thus,
S Strain → Inject into mice → Mice die
R Strain → Inject into mice → Mice live
Further, Griffith killed bacteria by heating them. He found that when heat – killed S Strain bacteria was injected, mice was alive (Please refer the image below). Further, after injecting a mixture of heat – killed S and live R bacteria, the mice died. Added to this, he was able to recover living S bacteria from the dead mice. Thus,
S Strain (Heat – killed) → Inject into mice → Mice live
S Strain (Heat + killed) + R Strain (live) → Inject into mice → Mice die
Thus, from the above experiment, Griffith reached to the conclusion that –
“R Strain bacteria had somehow transformed by heat – killed S strain bacteria. This was guided by some “transforming principle.” However, till this experiment, the biochemical nature of genetic material was not defined.”
Following diagram pictorially represents the entire experiment of Griffith. The above stated four reactions display the various conditions of mice in different stages.
R Strain → Inject into mice → Mice live
S Strain → Inject into mice → Mice die
S Strain (Heat – killed) → Inject into mice → Mice live
S Strain (Heat + killed) + R Strain (live) → Inject into mice → Mice die

Biochemical Characterization of Transforming Principle
Initially, protein was considered as genetic material. In the year 1933 – 44, Oswald Avery, Colin Macleod and Maclyn McCarty worked on the objective of determining the biochemical nature of “transforming principle.” So, they purified biochemicals like DNA, RNA, proteins, etc. from S cells in order to know which one can transform live R cells to S cells. They found –
- DNA from S bacteria is enough for transforming R bacteria.
- Proteases (protein digesting enzymes) and RNases (RNA digesting enzymes) have no effect on transformation. Thus, transforming substance was not RNA or protein.
Thus, they concluded that DNA was the only genetic material.
The Genetic Material is DNA (The Hershey – Chase experiments)
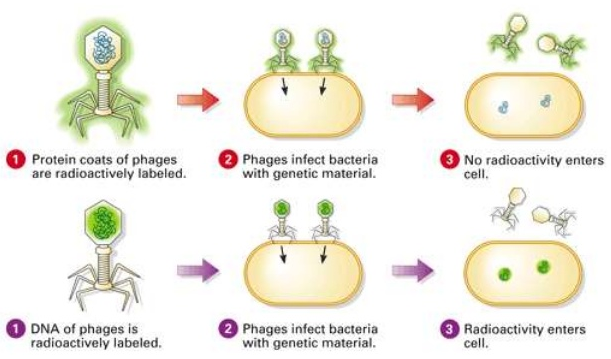
Alfred Hershey and Martha Chase in 1952 studied bacteriophage that proved that “DNA is the genetic material.” Bacteriophages are the viruses that can infect bacteria. These bacteriophages attaches to bacteria and its genetic material, thereby entering the bacterial cell. These cells treat viral genetic material and manufacture more virus particles. Hershey and Chase wanted to know whether it was DNA or protein from viruses that entered bacteria. Therefore, they grew some viruses in a special medium with radioactive phosphorus and some in the medium with radioactive sulfur.
Those radioactive phages were then allowed to associate to E.Coli bacteria and as the infection increased, the viral coats were eliminated from bacteria agitating them in blender. Thereby, separation of virus particles was done by spinning them in a centrifuge.
Those, bacteria which were infected by virus with radioactive DNA were radioactive, that helped in concluding that DNA is the material that was transferred from virus to bacteria. Added to this, the bacteria infected by radioactive protein were not radioactive. Thereby, this concluded that protein in not transferred from virus to bacteria.
Following figure shows all the steps of the Hershey – Chase experiments, which include infection at first, followed by blending and centrifugation. This experiment helped in concluding that DNA is the genetic material while protein in not the material that passed.
RNA World
RNA was the first genetic material. There are several evidences that suggest that essential life processes are evolved around RNA. RNA used to act as catalyst and genetic material. But RNA being a catalyst was reactive and therefore, unstable. This resulted in the evolution of DNA which is more stable. DNA is double stranded and resists change by evolving the process of repair.
What is DNA Replication?
“DNA replication is the process by which DNA makes a copy of itself during cell division.”
Steps of DNA Replication
- At the first step, DNA ‘unzips’ its double helical structure. This is carried out by an enzyme called helicase. This helps in breaking of hydrogen bonds that hold commentary bases of DNA.
- The separation of two strands creates ‘Y’ shape called a replication fork. These two separated strands act as a template for making the new strands of DNA.
- One of strand is oriented in 3’ to 5’ direction which is referred as leading strand, while other strand is oriented in 5’ to 3’ direction referred as lagging strand. Due to this different orientation, the two strands replicated differently.
Following figure shows the replication of leading and lagging strands of DNA as discussed.
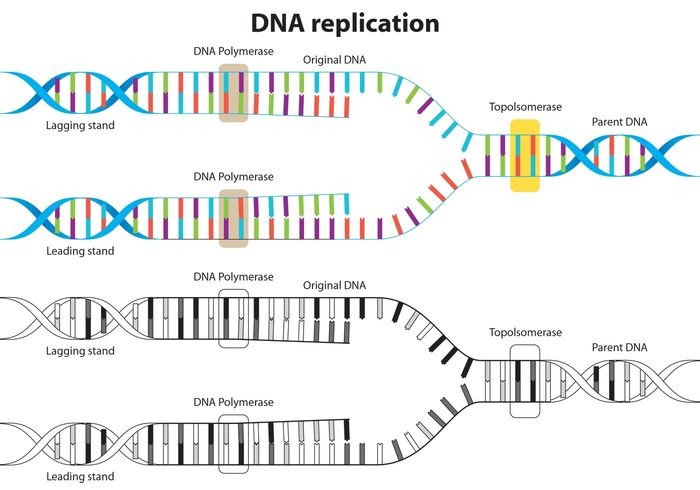
| Leading strand | Lagging strand |
|
|
|
|
|
|
- After matching of all the bases, i.e. A – T and C – G, enzyme called exonuclease strips away the primer and those gaps were filled by complementary nucleotides.
- The newly formed strand is proofread in order to make sure that there is no mistake in the sequencing of DNA.
- In the end, DNA ligase, seals up the sequence of DNA into two continuous double strands. The result of this DNA replication is generation of two DNA molecules consisting of one new and one old chain of nucleotide. This scheme is referred as semiconservative DNA replication.
Definition of Transcription
“The process of copying genetic information from one strand of the DNA into RNA is termed as transcription.”
The process of transcription is governed by the principle of complementarity, except adenosine which forms base pair with uracil rather than thymine. Unlike the process of replication, in which total DNA is duplicated, in case of transcription, only a segment of DNA and only one strand is copied into RNA.
Transcription Unit
The transcription unit in DNA is defined primarily by three regions in DNA –
- A promoter
- The structural gene
- A terminator
Following diagram shows the Transcription process-
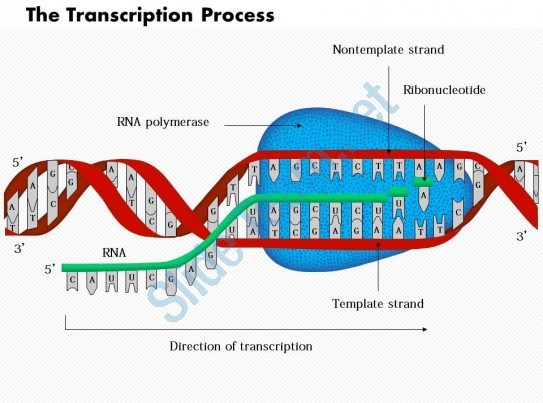
Overview of Transcription
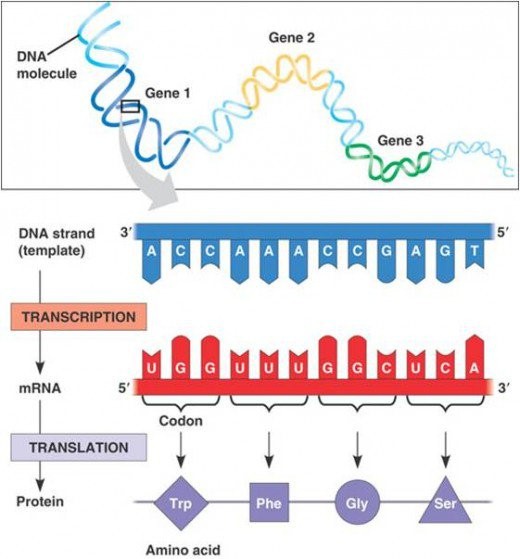
It is the first step of gene expression. At this step, the information from a gene is used to form a functional product called protein. The main objective of transcription is to make the copy of RNA of gene’s DNA sequence. In case of protein coding gene, transcript or RNA copy carry the information required to form polypeptide.
Following figure shows the process of transcription and translation. In former, RNA makes the copy of DNA sequencing and this transcript carries the information required to form a polypeptide.
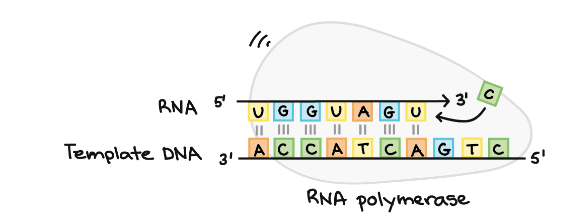
RNA polymerase
It is the main enzyme involved in the process of transcription. It uses single stranded DNA template to form complementary strand of RNA. To be specific, RNA polymerase form RNA strand in 5’ to 3’ direction, by adding each new nucleotide to the 3’ end of the strand.
Following diagrams shows RNA polymerase as discussed in the above paragraph–
Stages of Transcription
Transcription of a gene is carried out in three stages, i.e. initiation, elongation and termination.
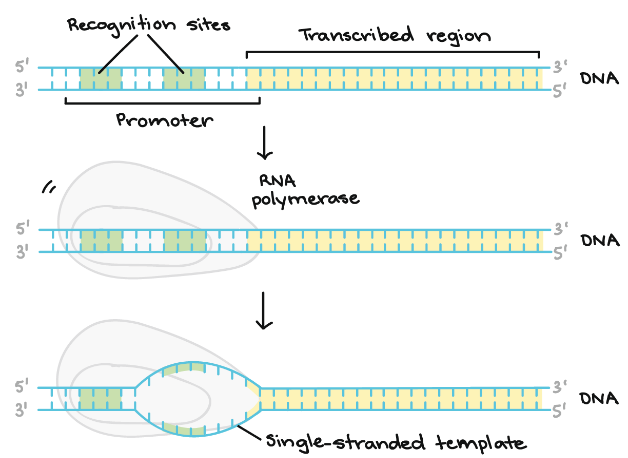
- Initiation – RNA polymerase binds itself to the sequence of DNA (called promoter) that is found near the beginning of a gene. Each gene has its own promoter and once bound, DNA strands gets separated from RNA polymerase providing the single stranded template required for transcription.
Following diagram shows the initiation stage in detail whereby, we can see the formation of single – stranded template.
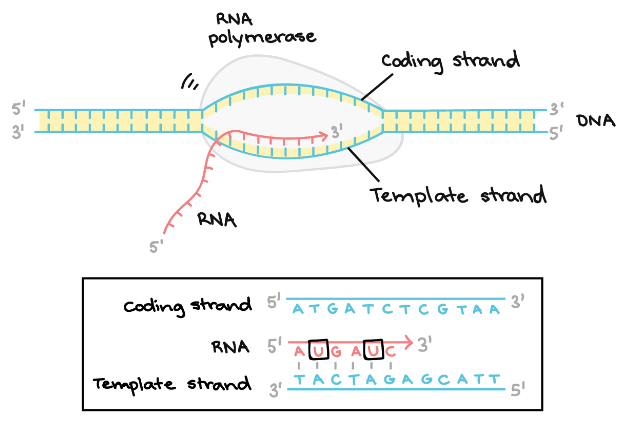
- Elongation – The template strand act as a template for RNA polymerase and as it refer this template, the polymerase build a RNA molecule out of complementary nucleotides, forming a chain which grows from 5’ to 3’. The same information is carried by RNA transcript in the form of non – template strand of DNA, with the bases Uracil (U) in spite of Thymine (T).
Following diagram explains the elongation stage in detail, as discussed-
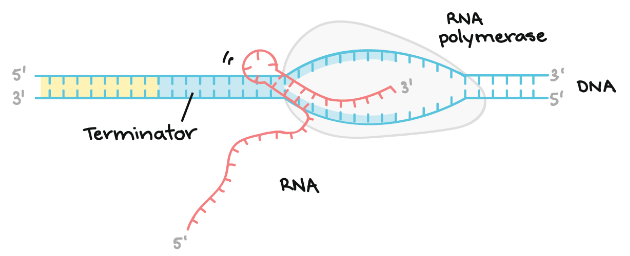
Termination – Terminators signals after the completion of RNA and once the sequences are transcribed, they result in releasing of transcript from RNA polymerase.
Following diagram demonstrates the termination stage, which includes formation of a hairpin in the RNA –
Definition of Genetic Code
“The genetic code is the set of rules by which information encoded within genetic material (DNA or mRNA sequences) is translated into proteins by living cells.”
During replication and transcription, one nucleic acid was copied forming another nucleic acid. On the other hand, during translation, transfer of genetic information is carried out from a polymer of nucleotides to polymer of amino acid. Thus, it can be said that genes are expressed in two steps –
- During transcription, the DNA sequence of a gene is rewritten in RNA and in case of eukaryotes, RNA goes through additional processing steps to become m-RNA.
- During translation, the sequence of nucleotides is translated into sequence of amino acids in protein chain.
Definition of Codon
“Cells decode mRNAs by reading their nucleotides in groups of three, called codons.”
Example of Codon
AUG, ATG, etc.
Several features of codon are as follows:
- Most codons specify amino acids.
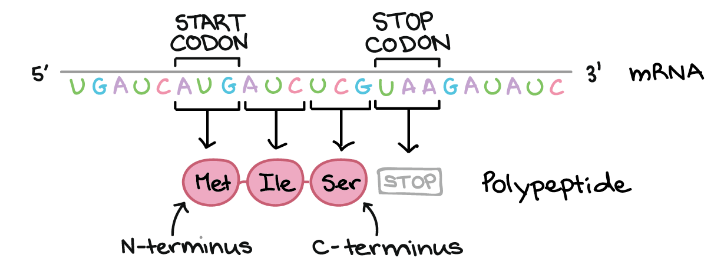
- 3 “STOP” codon mark the end of protein.
- 1 “START” codon, AUG, is the beginning of protein and amino acid methionine is encoded.
- One codon codes form only 1 amino acid and therefore, it is specific in nature.
- Some amino acids are coded via more than one codon and thus, code is degenerate.
During translation, codon in mRNA is read, beginning with start codon, and continuing until stop codon is reached. These codons are read from 5’ to 3’ and specify the order of amino acid in proteins from N – terminus to C – terminus. Following figure illustrates working of codons as discussed-
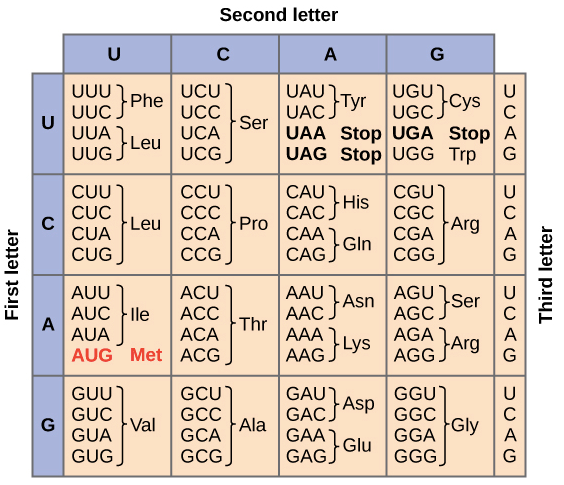
Definition of Genetic Code Table
“The full set of relationships between codons and amino acids (or stop signals) is called the Genetic Code.”
Following table summarizes the genetic code. We can observe that many amino acids are represented in the table by more than one codon. For example, we can see there are six different methods to write Leucine in the language of mRNA.
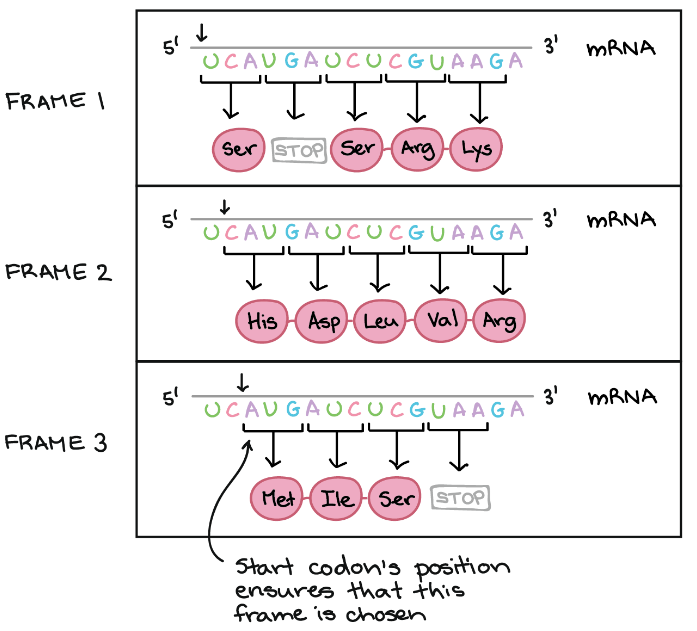
Reading Frame
Reading frame helps in determining the way by which mRNA sequence is divided into codons during translation.
Example of Reading Frame
In the below diagram, mRNA can encode three totally different proteins, on the basis of frame. Three different frames can be produced and start of codon’s position ensures which frame is to be chosen. Here the start codon is the key signal because translation starts at this codon and continues successively in the group of three.
Definition of Translation
“Translation refers to the process of polymerization of amino acids to form a polypeptide.”
The order and sequence of amino acids are defined by the sequence of bases in mRNA and these amino acids are joined via peptide bond. The peptide bond is formed by the usage of energy and therefore, in the first step amino acids are activated and linked to cognate tRNA (referred as charging of tRNA or aminoacylation of tRNA). When these charged tRNAs are brought close, peptide bond is formed and this formation is catalyzed that enhances the rate of peptide bond formation.
Frequently Asked Question (FAQs)
Q1. What is the difference between DNAs and DNase?
Sol. DNA is the heredity material in humans and in almost all organisms while DNase is an enzyme that catalyzes the hydrolytic cleavage of phosphodiester linkages in the DNA backbone. DNA is present in nucleus while DNase is present in cytoplasm of cell. Lastly, DNA helps in transferring genetic information from one generation to another but DNase is used to cleavage DNA molecules during recombinant DNA technology.
Q2. What is the difference between DNA and RNA?
Sol.
| DNA | RNA |
| DNA occurs inside nucleus and in some cell organelles like mitochondria and chloroplast in plants. | Very little RNA is present in nucleus while majority is found in cytoplasm. |
| It is double stranded with very few exceptions in case of viruses. | It is single stranded with exception of some virus called Reovirus |
| DNA comprise of millions of nucleotides. | On the basis of type, RNA comprise of 70 – 12,000 nucleotides. |
| 2 – Deoxyribose is the sugar portion of DNA. | Ribose is the sugar portion of RNA. |
| The numbers of Purine and Pyrimidine bases are equal. | There is no proportionality in the number of Purine and Pyrimidine bases. |
The base present in DNA are – Adenine (A), Guanine (G), Thymine (T) and Cytosine (C). | The base present in RNA are – Adenine (A), Guanine (G), Uracil (U) and Cytosine (C). |
| Hydrogen bonds are formed between complementary nitrogen bases of opposite strands, i.e. A-T and C-G. | Base pairing via hydrogen bonds occurs only in coiled parts. |
| DNA produce regular helix and is therefore, spirally twisted. | The strands of RNA may be folded to produce secondary helix or pseudo helix. |
| DNA replicates to form new DNA molecules. | RNA cannot replicate on its own. |
| It occurs in the form of chromosomes or chromatin. | It occurs in ribosomes or forms associated with ribosomes. |
| DNA transfers genetic information from one generation to another. | It directs the synthesis of proteins in body. |
| DNA transcribes genetic information to RNA and it has fixed quantity. | It is responsible to translating the transcribed messages for forming polypeptides. The quantity of RNA cells is variable. |
| DNA is of two types, i.e. intra nuclear and extra nuclear. | RNA is of three types, i.e. m – RNA, t – RNA and r – RNA. |
| It is long lived. | It is short lived. |
Q3. What are the characteristics or properties of genetic material?
Sol. For a substance to be a genetic material, it must have following properties –
- The substance must present in every cell and must be structurally and chemically stable.
- It must comprise of all biologically useful information.
- It must have the capability of storing information in coded form in order to control biological functions of cells and it must have the ability to express its information.
- It must portray diversity corresponding to the variety existing in organisms.
- It must replicate precisely, and must be able to pass over the true copies to the successive generation.
- It must undergo mutation and recombination and these variations must be inheritable and stable.
- The genetic substance must possess the ability to generate new kind and its own kind of molecules.
- It must possess the capability of differential expression.
Q4. Why strands are not copied during transcription?
Sol. This is so because:
- If both strands will act as template, they would code RNA molecule with different sequences. While, if they code for proteins, the sequence of amino acids in the protein would be not be same. Therefore, one strand of DNA would be coding two different proteins, and this will add complexity to the transfer machinery of genetic information.
- Secondly, the two RNA molecules, if produced simultaneously would be complementary to each other and therefore, will form double stranded RNA. This will prevent RNA from being translating into proteins and the process of transcription will become futile.
Q5. What is meant by regulation of gene expression
Sol. Regulation of gene expression occurs at various levels. In case of eukaryotes, regulation could be exerted at –
- Transcriptional level
- Processing level
- Translational level
- Transport of mRNA to cytoplasm from nucleus.
In case of prokaryotes, control of rate of transcriptional initiation is the predominant site for the control of gene expression.