We are aware of the concepts of Inheritance, its pattern and genetic basis. As we know that the genetic basis resides in nucleic acid found in living beings. There are two types of nucleic acids:
- Deoxyribonucleic Acid (DNA)
- Ribonucleic Acid (RNA)
In living organisms, DNA act as the genetic material and RNA act as genetic material in some viruses, and play the role of messenger. DNA is located in nucleus primarily, and is also found in cell structures called mitochondria.
DNA
DNA was first isolated by Friedrich Miescher in the year 1869 and Francis Crick and James Watson identified its molecular structure in 1953.
Definition of DNA
“Deoxyribonucleic acid is a molecule that carries the genetic instructions used in growth, development, functioning and reproduction of all known Living Organisms and many viruses.” It is a long polymer of deoxyribonucleotides and length of DNA depends on the number of nucleotides present in it. Most DNA molecule has two biopolymer strands coiled around each other to form double helix. These two DNA strands are termed as polynucleotides as they are composed of simple monomer units, that is. nucleotides.
Each nucleotide is composed of one of 4 nitrogen – containing nucleobases (such as cytosine (C), adenine (A), guanine (G) and thymine (T)), a phosphate group and a sugar called deoxyribose. These nucleotides are connected via covalent bond forming a chain between sugar of one nucleotide and the phosphate of the next, thereby resulting in an alternating sugar – phosphate backbone.
Following figure shows the double helical structure of DNA with sugar – Phosphate backbone:
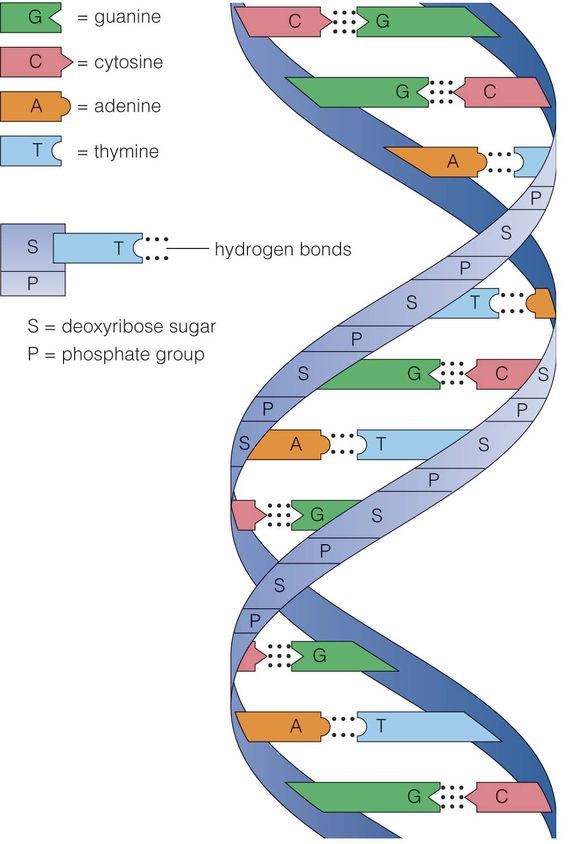
shows the double helical structure of DNA with sugar – phosphate backbone[/caption]DNA consists of biological information and its backbone are resistant to cleavage. Both the strands of DNA store same biological information and this information gets replicated when the two strands get separated. These two strands run in opposite direction and are antiparallel to each other.
Salient features of double helical structure of DNA
- DNA is composed of 2 polynucleotide chains and its backbone constitutes of sugar – phosphate and the bases project inside.
- Both the strands of DNA possess anti – parallel polarity. It implies, if the polarity of one strand is 5’à3’ then the other strand will be 3’à5’.
- The bases in strands are paired via hydrogen bond (H – bond). It is important to note that Adenine forms two hydrogen bonds with Thymine from opposite strand and vice – versa. In the same way, Guanine bonds with cytosine with 3H – bond. As a result, always purine comes opposite to a pyrimidine.
- The two strands or chain are coiled in right – handed fashion and the pitch of helix is 3.4nm and there are around 10 bp in each turn. Thus, the distance between a bp in a helix is around 0.34 nm.
- The plane of one base pair stacks over another in double helix and this in addition to H – bond results in the stability of the helical structure.
- The double helical structure has major and minor grooves along the phosphodiester backbone.
- The genetic information resides on one of the two strands called sense strand or template strand.
- H – Bond is formed between purine and pyrimidine only. The one base arrangement possible in the structure of DNA are A – T, T – A, G – C and C – G.
Following figure shows the double stranded polynucleotide chain with all the features as discussed above, that is. 2 polynucleotide chains, its backbone with sugar – phosphate bond and its base arrangement (A – T, T – A, G – C and C – G)
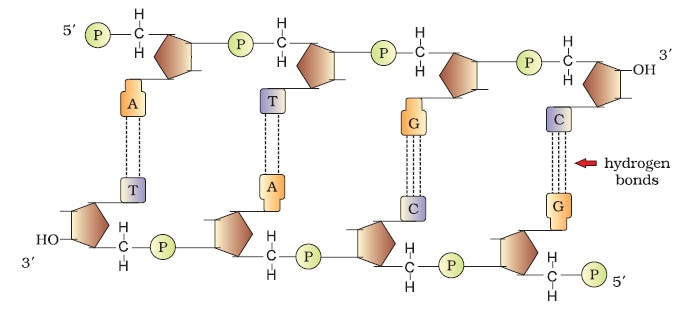
“Each chromosome consists of one continuous thread – like molecule of DNA coiled tightly around proteins, and contains a portion of the 6,400,000,000 base pairs (DNA building blocks) that make up your DNA.” The manner in which DNA is packaged into chromatin is the factor that control the production of protein.
Packaging of DNA Helix
- Packaging in Prokaryotes – In prokaryotes well – defined nucleus is not present absent and therefore, DNA is held together with some proteins in a region called nucleoid. Here, the DNA is organized in the form of large loops held by proteins.
- Packaging in Eukaryotes – The organization of DNA is complex in eukaryotes. In the year 1974, Reger Kornberg reported that chromosome is composed of protein and DNA. On the basis of presence of amino acid residue with charged side chains, a protein gains its charge. Histones are the proteins that are rich in arginine and lysine residues. Both these amino acids carry positively charged and organize themselves to make a unit of 8 molecules referred as Histone Octamer. The negatively charged DNA is wrapped around positively charged Histone Octamer to form the structure called nucleosome.
Following figure shows the structure of nucleosome. It is made up of four types of proteins – H2A, H2B, H3 and H4 occurring in pairs.
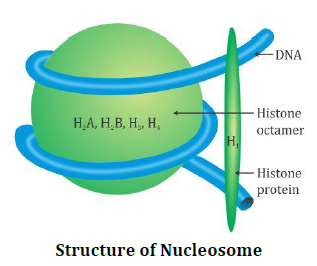
Structure of Nucleosome[/caption]One nucleosome comprise of 200 base pair of DNA helix and these are repeating units of chromatin which are thread like colored bodies in nucleus. When observed under electron microscope, it appears as “beads on string.”
Non – Histone Chromosomal Proteins
These are additional set of proteins which contribute to the packaging of chromatin at higher level. Following regions are present in chromatin –
- Euchromatin – It is loosely packed in a typical nucleus. It is transcriptionally active.
- Heterochromatin – These are densely packed and are stains dark. It is transcriptionally inactive.
Search of Genetic Material
Transforming Principle – It was an early name for DNA. In the year 1928, scientists were not aware that DNA carried genetic information but they were aware that there was something that causes bacteria to transform from one form to another.
Frederick Griffith in the year 1928 carried out an experiment on pneumococcus bacteria. These bacteria were of two types, that is. smooth type(S) and rough type (R). When Streptococcus pneumoniae bacteria were grown on a culture plate, some produced rough colonies while some produced smooth shiny colonies. This is so because the S strain bacteria consist of polysaccharide (mucous) coat, while R was not having any coat. When a mouse was infected with S strain, they died due to pneumonia infection but mice infected with R strain do not developed any infection (Please refer the image below). Thus,
S Strain → Inject into mice → Mice die
R Strain → Inject into mice → Mice live
Further, Griffith killed bacteria by heating them. He found that when heat – killed S Strain bacteria was injected, mice was alive (Please refer the image below). Further, after injecting a mixture of heat – killed S and live R bacteria, the mice died. Added to this, he was able to recover living S bacteria from the dead mice. Thus,
S Strain (Heat – killed) → Inject into mice → Mice live
S Strain (Heat + killed) + R Strain (live) → Inject into mice → Mice die
Thus, from the above experiment, Griffith reached to the conclusion that –
“R Strain bacteria had somehow transformed by heat – killed S strain bacteria. This was guided by some “transforming principle.” However, till this experiment, the biochemical nature of genetic material was not defined.”
Following diagram pictorially represents the entire experiment of Griffith. The above stated four reactions display the various conditions of mice in different stages.
R Strain → Inject into mice → Mice live
S Strain → Inject into mice → Mice die
S Strain (Heat – killed) → Inject into mice → Mice live
S Strain (Heat + killed) + R Strain (live) → Inject into mice → Mice die

Biochemical Characterization of Transforming Principle
Initially, protein was considered as genetic material. In the year 1933 – 44, Oswald Avery, Colin Macleod and Maclyn McCarty worked on the objective of determining the biochemical nature of “transforming principle.” So, they purified biochemicals like DNA, RNA, proteins, etc. from S cells in order to know which one can transform live R cells to S cells. They found –
- DNA from S bacteria is enough for transforming R bacteria.
- Proteases (protein digesting enzymes) and RNases (RNA digesting enzymes) have no effect on transformation. Thus, transforming substance was not RNA or protein.
Thus, they concluded that DNA was the only genetic material.
The Genetic Material is DNA (The Hershey – Chase experiments)
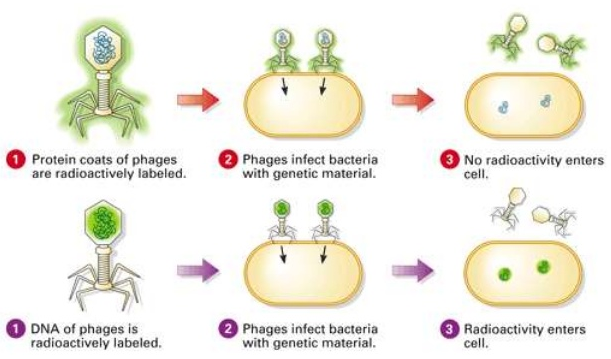
Alfred Hershey and Martha Chase in 1952 studied bacteriophage that proved that “DNA is the genetic material.” Bacteriophages are the viruses that can infect bacteria. These bacteriophages attaches to bacteria and its genetic material, thereby entering the bacterial cell. These cells treat viral genetic material and manufacture more virus particles. Hershey and Chase wanted to know whether it was DNA or protein from viruses that entered bacteria. Therefore, they grew some viruses in a special medium with radioactive phosphorus and some in the medium with radioactive sulfur.
Those radioactive phages were then allowed to associate to E.Coli bacteria and as the infection increased, the viral coats were eliminated from bacteria agitating them in blender. Thereby, separation of virus particles was done by spinning them in a centrifuge.
Those, bacteria which were infected by virus with radioactive DNA were radioactive, that helped in concluding that DNA is the material that was transferred from virus to bacteria. Added to this, the bacteria infected by radioactive protein were not radioactive. Thereby, this concluded that protein in not transferred from virus to bacteria.
Following figure shows all the steps of the Hershey – Chase experiments, which include infection at first, followed by blending and centrifugation. This experiment helped in concluding that DNA is the genetic material while protein in not the material that passed.
RNA World
RNA was the first genetic material. There are several evidences that suggest that essential life processes are evolved around RNA. RNA used to act as catalyst and genetic material. But RNA being a catalyst was reactive and therefore, unstable. This resulted in the evolution of DNA which is more stable. DNA is double stranded and resists change by evolving the process of repair.
What is DNA Replication?
“DNA replication is the process by which DNA makes a copy of itself during cell division.”
Steps of DNA Replication
- At the first step, DNA ‘unzips’ its double helical structure. This is carried out by an enzyme called helicase. This helps in breaking of hydrogen bonds that hold commentary bases of DNA.
- The separation of two strands creates ‘Y’ shape called a replication fork. These two separated strands act as a template for making the new strands of DNA.
- One of strand is oriented in 3’ to 5’ direction which is referred as leading strand, while other strand is oriented in 5’ to 3’ direction referred as lagging strand. Due to this different orientation, the two strands replicated differently.
Following figure shows the replication of leading and lagging strands of DNA as discussed.
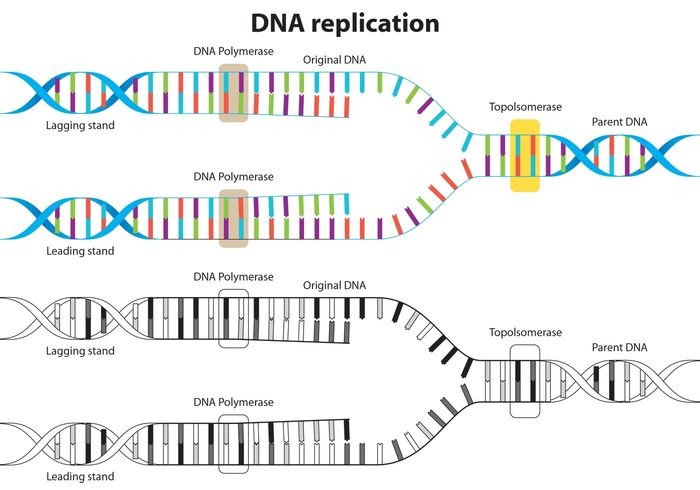
| Leading strand | Lagging strand |
|
|
- After matching of all the bases, i.e. A – T and C – G, enzyme called exonuclease strips away the primer and those gaps were filled by complementary nucleotides.
- The newly formed strand is proofread in order to make sure that there is no mistake in the sequencing of DNA.
- In the end, DNA ligase, seals up the sequence of DNA into two continuous double strands. The result of this DNA replication is generation of two DNA molecules consisting of one new and one old chain of nucleotide. This scheme is referred as semiconservative DNA replication.
Definition of Transcription
“The process of copying genetic information from one strand of the DNA into RNA is termed as transcription.”
The process of transcription is governed by the principle of complementarity, except adenosine which forms base pair with uracil rather than thymine. Unlike the process of replication, in which total DNA is duplicated, in case of transcription, only a segment of DNA and only one strand is copied into RNA.
Transcription Unit
The transcription unit in DNA is defined primarily by three regions in DNA –
- A promoter
- The structural gene
- A terminator
Following diagram shows the Transcription process-
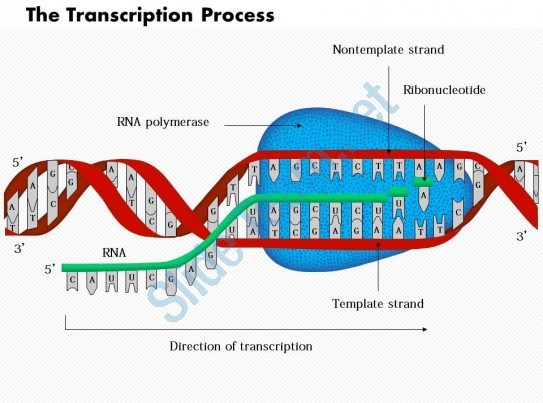
Overview of Transcription
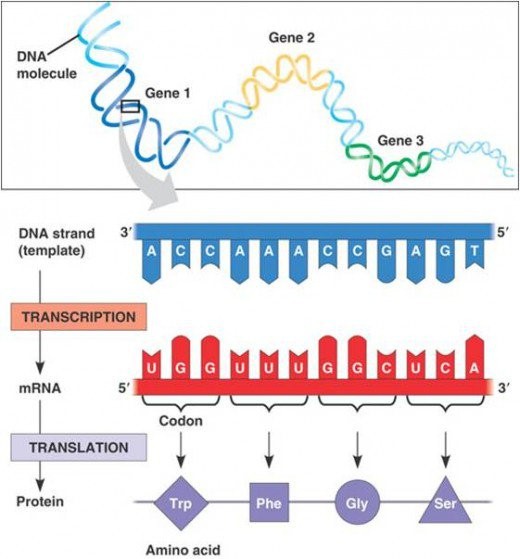
It is the first step of gene expression. At this step, the information from a gene is used to form a functional product called protein. The main objective of transcription is to make the copy of RNA of gene’s DNA sequence. In case of protein coding gene, transcript or RNA copy carry the information required to form polypeptide.
Following figure shows the process of transcription and translation. In former, RNA makes the copy of DNA sequencing and this transcript carries the information required to form a polypeptide.
RNA polymerase
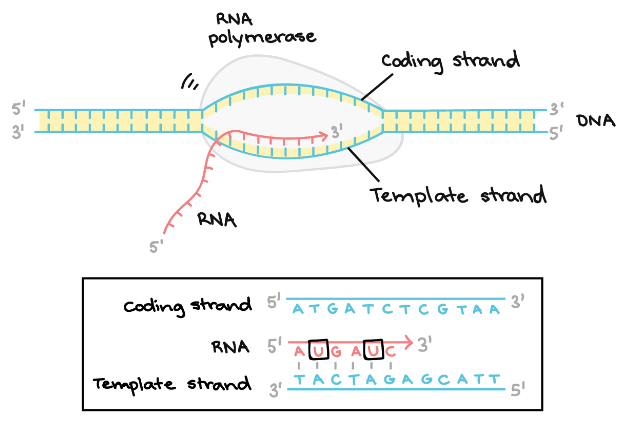
It is the main enzyme involved in the process of transcription. It uses single stranded DNA template to form complementary strand of RNA. To be specific, RNA polymerase form RNA strand in 5’ to 3’ direction, by adding each new nucleotide to the 3’ end of the strand.
Following diagrams shows RNA polymerase as discussed in the above paragraph–
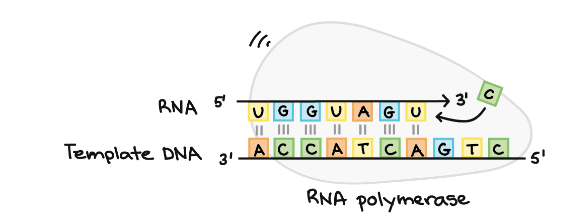
Stages of Transcription
Transcription of a gene is carried out in three stages, i.e. initiation, elongation and termination.
- Initiation – RNA polymerase binds itself to the sequence of DNA (called promoter) that is found near the beginning of a gene. Each gene has its own promoter and once bound, DNA strands gets separated from RNA polymerase providing the single stranded template required for transcription.
Following diagram shows the initiation stage in detail whereby, we can see the formation of single – stranded template.
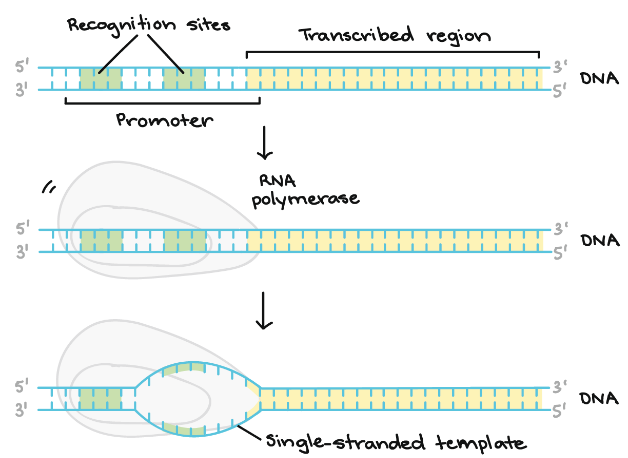
- Elongation – The template strand act as a template for RNA polymerase and as it refer this template, the polymerase build a RNA molecule out of complementary nucleotides, forming a chain which grows from 5’ to 3’. The same information is carried by RNA transcript in the form of non – template strand of DNA, with the bases Uracil (U) in spite of Thymine (T).
Following diagram explains the elongation stage in detail, as discussed-
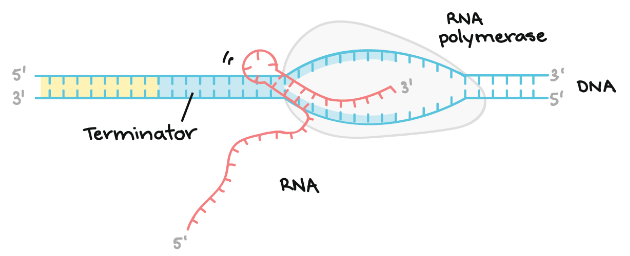
Termination – Terminators signals after the completion of RNA and once the sequences are transcribed, they result in releasing of transcript from RNA polymerase.
Following diagram demonstrates the termination stage, which includes formation of a hairpin in the RNA –
Definition of Genetic Code
“The genetic code is the set of rules by which information encoded within genetic material (DNA or mRNA sequences) is translated into proteins by living cells.”
During replication and transcription, one nucleic acid was copied forming another nucleic acid. On the other hand, during translation, transfer of genetic information is carried out from a polymer of nucleotides to polymer of amino acid. Thus, it can be said that genes are expressed in two steps –
- During transcription, the DNA sequence of a gene is rewritten in RNA and in case of eukaryotes, RNA goes through additional processing steps to become m-RNA.
- During translation, the sequence of nucleotides is translated into sequence of amino acids in protein chain.
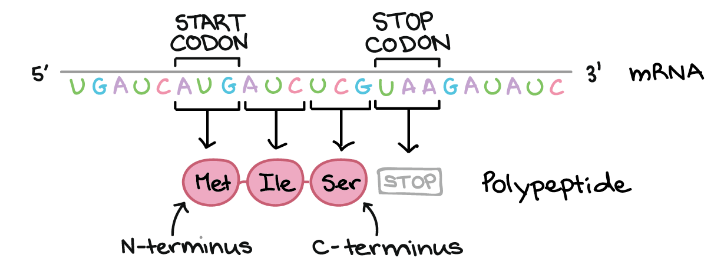
Definition of Codon
“Cells decode mRNAs by reading their nucleotides in groups of three, called codons.”
Example of Codon
AUG, ATG, etc.
Several features of codon are as follows:
- Most codons specify amino acids.
- 3 “STOP” codon mark the end of protein.
- 1 “START” codon, AUG, is the beginning of protein and amino acid methionine is encoded.
- One codon codes form only 1 amino acid and therefore, it is specific in nature.
- Some amino acids are coded via more than one codon and thus, code is degenerate.
During translation, codon in mRNA is read, beginning with start codon, and continuing until stop codon is reached. These codons are read from 5’ to 3’ and specify the order of amino acid in proteins from N – terminus to C – terminus. Following figure illustrates working of codons as discussed-
Definition of Genetic Code Table
“The full set of relationships between codons and amino acids (or stop signals) is called the Genetic Code.”
Following table summarizes the genetic code. We can observe that many amino acids are represented in the table by more than one codon. For example, we can see there are six different methods to write Leucine in the language of mRNA.
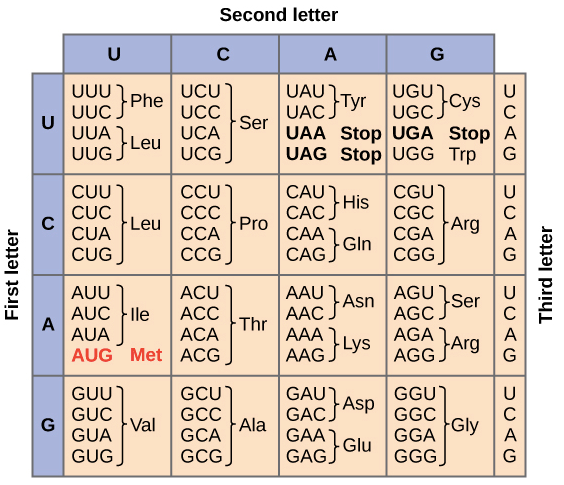
Reading Frame
Reading frame helps in determining the way by which mRNA sequence is divided into codons during translation.
Example of Reading Frame
In the below diagram, mRNA can encode three totally different proteins, on the basis of frame. Three different frames can be produced and start of codon’s position ensures which frame is to be chosen. Here the start codon is the key signal because translation starts at this codon and continues successively in the group of three.
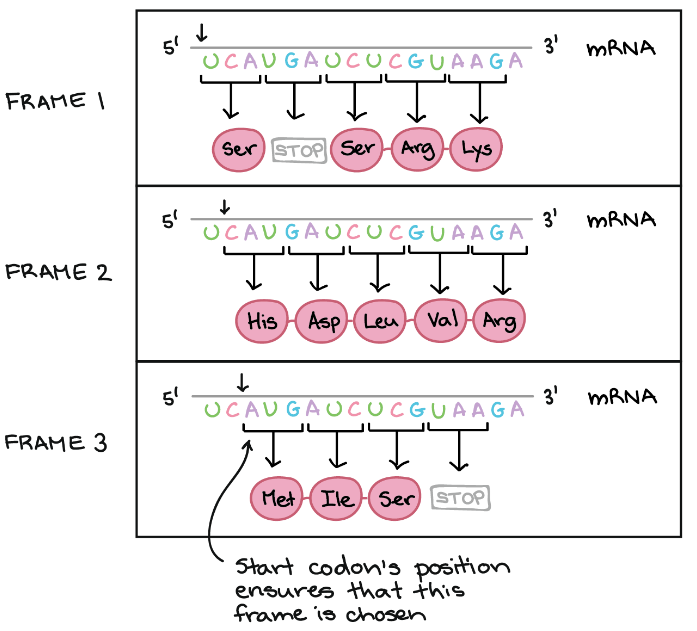
Definition of Translation
“Translation refers to the process of polymerization of amino acids to form a polypeptide.”
The order and sequence of amino acids are defined by the sequence of bases in mRNA and these amino acids are joined via peptide bond. The peptide bond is formed by the usage of energy and therefore, in the first step amino acids are activated and linked to cognate tRNA (referred as charging of tRNA or aminoacylation of tRNA). When these charged tRNAs are brought close, peptide bond is formed and this formation is catalyzed that enhances the rate of peptide bond formation.
Topic 3.2: Chromosomes
In the Chromosomes unit students learn the structure of the chromosome and identify the consequences of a base substitution mutation.
The unit is planned to take 3 school days
Essential idea:
- Chromosomes carry genes in a linear sequence that is shared by members of a species. 3.
Nature of science:
- Developments in research follow improvements in techniques—autoradiography was used to establish the length of DNA molecules in chromosomes. (1.8)
- Outline the advancement in knowledge gained from the development of autoradiography techniques.
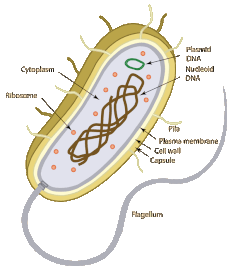
3.2.U1 Prokaryotes have one chromosome consisting of a circular DNA molecule. (Oxford Biology Course Companion page 18).
- Describe the arrangement of prokaryotic DNA (nucleoid and plasmid).
- Define the term “naked” in relation to prokaryotic DNA
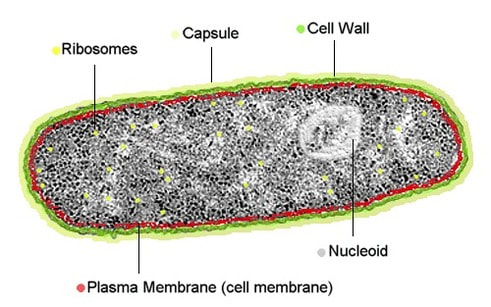
Prokaryotes do not possess a nucleus – instead genetic material is found free in the cytoplasm in a region called the nucleoid
The genetic material of a prokaryote consists of a single chromosome consisting of a circular DNA molecule (genophore)
The DNA of prokaryotic cells is naked – meaning it is not associated with proteins for additional packagingProkaryotes have one chromosome consisting of a circular DNA molecule
- Circular DNA molecule contains all the genes needed for the basic life processes of the cell
- DNA in bacteria is not related/does not work with proteins therefore is described as naked
- 1 chromosome is present in a prokaryotic cell, there is usually only a single copy of each gene, there are two identical copies briefly after the chromosome has been replicated but this is in preparation for cell division.
- the two identical chromosomes are moved to opposite poles and the cell then splits in two
 |  |
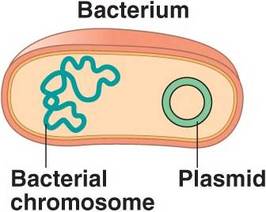
3.2.U2 Some prokaryotes also have plasmids but eukaryotes do not. Oxford Biology Course Companion page 150).
- Describe the structure and function of plasmid DNA.
Plasmids are small, circular DNA molecules that contain only a few genes and are capable of self-replication. Plasmids are present in some prokaryotic cells, but are not naturally present in eukaryotic cells
- Plasmids are small extra DNA molecules that are found in prokaryotes, very unusual in eukaryotes
- Described as circular and naked, containing very few genes that are useful to the cell but are not needed for basic life processes
- Plasmids are not always formed at the same time as the chromosome of a prokaryotic cells or at the same rate, therefore there can be multiple copies of plasmids in a cell and it may not be passed to both cells formed by cell division
- Gene transfer between species – copies of plasmids can be transferred from one cell to another, allowing spread through a population. It is possible that the plasmids can cross through species barrier, happens when plasmid is released when a prokaryotic cell dies and is then absorbed by a cell of a different species
 |  |
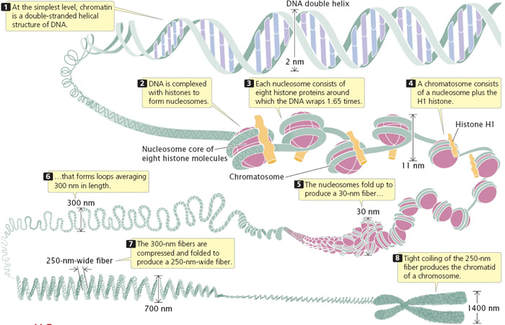
3.2.U3 Eukaryote chromosomes are linear DNA molecules associated with histone proteins (Oxford Biology Course Companion page 151).
- Describe the structure of eukaryotic DNA and associated histone proteins during interphase (chromatin).
- Explain why chromatin DNA in interphase is said to look like “beads on a string
- Chromosomes in eukaryotes are made up of DNA/ protein
- DNA is a long/ single linear DNA molecules
- Related with histone proteins – which are globular in shape and wider than the DNA
- There are many of these histone molecules in a chromosome with DNA molecules wrapped around them
- Adjacent histones in the chromosome are separated by short stretches of the DNA molecule that are not in contact with histones – this is why the eukaryotic chromosome looks like a string of beads during interphase
3.2.U4 In a eukaryote species there are different chromosomes that carry different genes.
- List three ways in which the types of chromosomes within a single cell are different.
- State the number of nuclear chromosome types in a human cell.
Eukaryotic chromosomes are linear molecules of DNA that are compacted during cell division (mitosis or meiosis). Each chromosome has a constriction point called a centromere, which divides the chromosome into two sections (or ‘arms’). The shorter section is designated the p arm and the longer section is designated the q arm. The genetic material of eukaryotic cells consist of multiple linear molecules of DNA that are associated with histone proteins
The packaging of DNA with histone proteins results in a greatly compacted structure, allowing for more efficient storage
- Eukaryotic chromosomes are too narrow to be visible with a light microscope during interphase –> then become visible during mitosis and meiosis because the chromosomes because shorter and fatter by supercoiling, they become visible only if stains that bind either DNA or proteins are used
- 1st stage of mitosis – chromosomes can be seen in double because there are two chromatids, that have identical DNA molecules produced by replication
- Chromosomes during mitosis can be seen differently whether they are different in length and/or in the position of the centromere where the two chromatids are held together
- in eukaryotes there are around two different types but in humans there are 23 different types of chromosomes
- Each gene in the eukaryotes has a different/certain position on one type of chromosome, called the locus of the gene
- Each chromosome type therefore carries a specific sequence of genes arranged along the linear DNA molecule – this can contain over a thousand genes
3.2.U5 Homologous chromosomes carry the same sequence of genes but not necessarily the same alleles of those genes.
- Define homologous chromosome.
- State a similarity and a difference found between pairs of homologous chromosomes.
Sexually reproducing organisms inherit their genetic sequences from both parents . This means that these organisms will possess two copies of each chromosome (one of maternal origin ; one of paternal origin). These maternal and paternal chromosome pairs are called homologous chromosomes
Homologous chromosomes are chromosomes that share:
- The same structural features (e.g. same size, same banding patterns, same centromere positions)
- The same genes at the same loci positions (while the genes are the same, alleles may be different)homologous are two chromosomes that have the same sequence of genes
They are not identical to each other because some of the genes on them, the alleles are different
The species can be interbreed – if 2 eukaryotes are members of the same species we can expect each of the chromosomes in one of them to be homologous with at least one chromosome in the other.
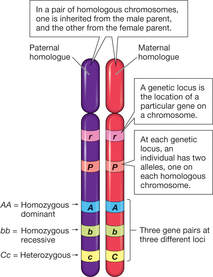
3.2.U6 Diploid nuclei have pairs of homologous chromosomes.
- Define diploid
- State the human cell diploid number
- Outline the formation of a diploid cell from two haploid gametes.
- State an advantage of being diploid.
Nuclei possessing pairs of homologous chromosomes are diploid (symbolised by 2n)
- Two chromosomes of each type
- In humans that means it contains 46 chromosomes
- Haploid gametes fuse together during sex, a zygote with a diploid nucleus is formed through mitosis it divides and more cells with diploid nuclei are produced, many animals and plants only consist of diploid cells
- Diploid nuclei have two copies of every gene, apart from the sex chromosomes
- A benefit of this is that harmful recessive mutations can be avoided if a dominant alleles is also present.
- HYBRID VIGOUR – organism are more vigorous if they have two different alleles of genes instead of one
3.2.U7 Haploid nuclei have one chromosome of each pair.
- Define haploid.
- State the human cell haploid number.
- List example haploid cells.
Nuclei possessing only one set of chromosomes are haploid (symbolised by n)
- They have one chromosome of each type
- Gametes – sex cells that fuse together during sexual reproduction
- gametes have haploid nuclei, so in humans both egg and sperm cells contain 23 chromosomes
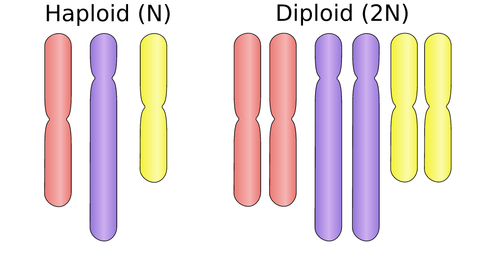
3.2.U8 The number of chromosomes is a characteristic feature of members of a species.
- State that chromosome number and type is a distinguishing characteristic of a species.
- List mechanisms by which a species chromosome number can change.
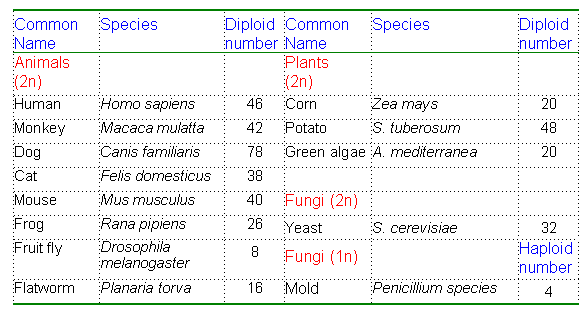
Chromosome number is a characteristic feature of members of a particular species. Organisms with different diploid numbers are unlikely to be able to interbreed (cannot form homologous pairs in zygotes)
- organisms with a different number of chromosomes are unlikely to be able to interbreed so all the interbreeding members of a species need to have the same number of chromosomes
- the number of chromosomes can change through time, if chromosomes become fused together or increase if splits occur
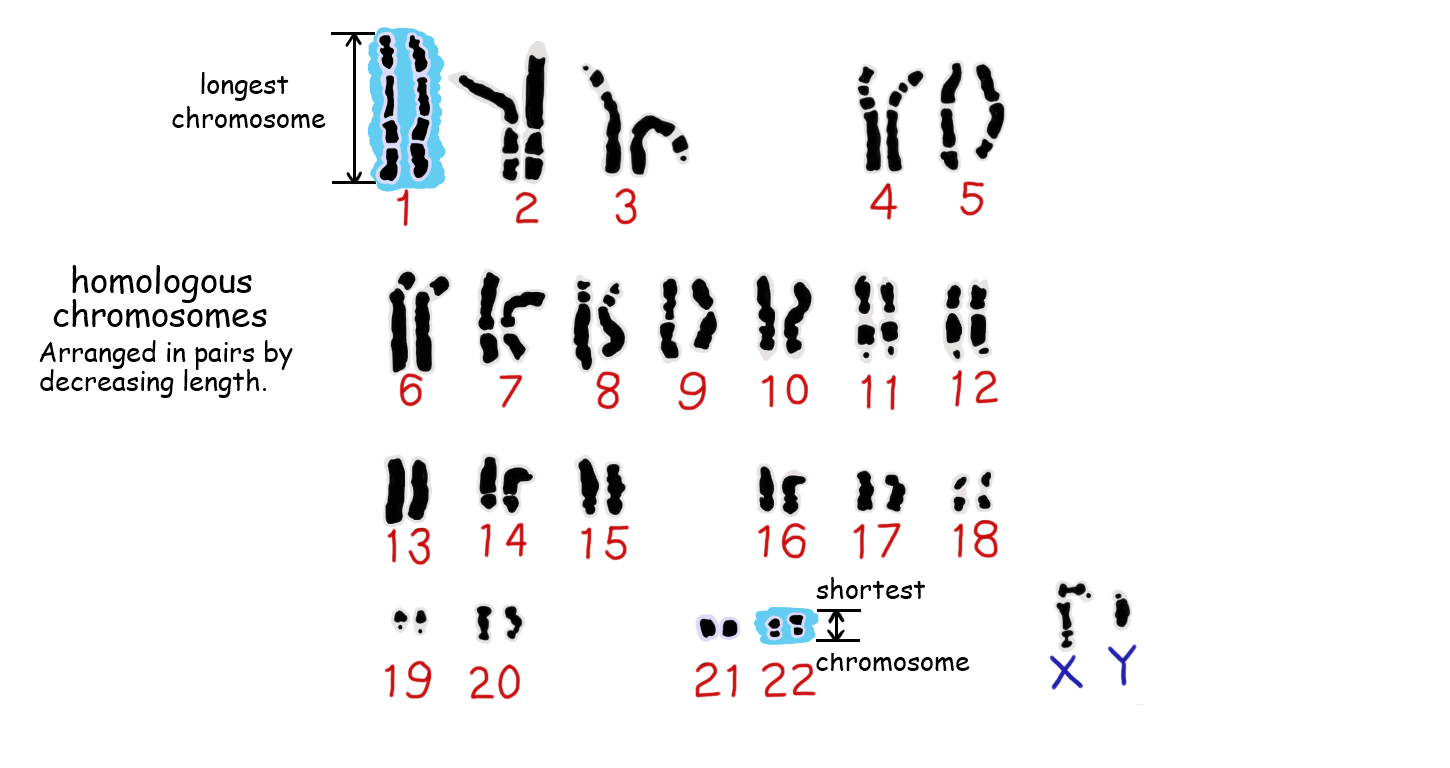
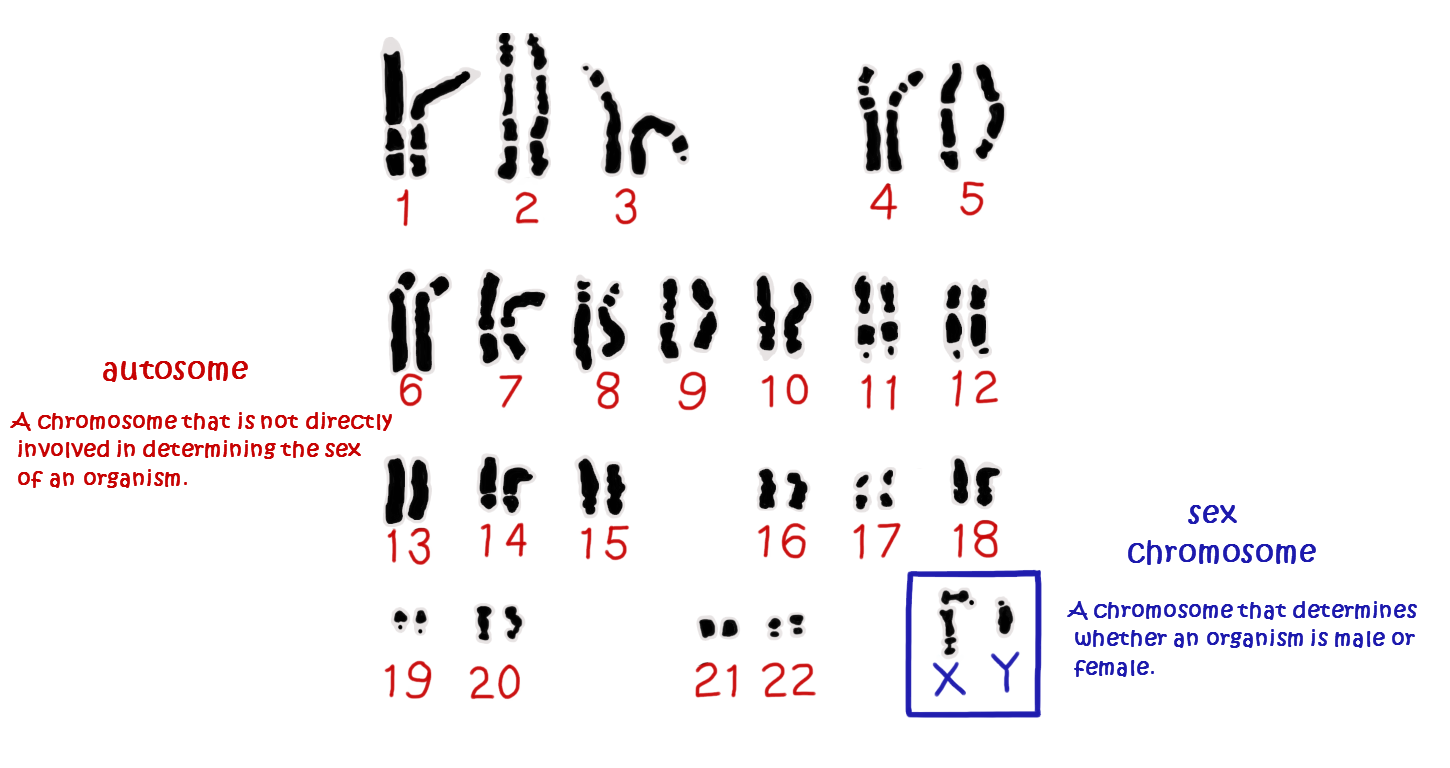
3.2.U9 A karyogram shows the chromosomes of an organism in homologous pairs of decreasing length.
- Describe the process of creating a karyogram.
- List the characteristics by which chromosomes are arranged on the karyogram.
Karyotypes are the number and types of chromosomes in a eukaryotic cell – they are determined via a process that involves:
- Harvesting cells (usually from a foetus or white blood cells of adults)
- Chemically inducing cell division, then arresting mitosis while the chromosomes are condensed
- The stage during which mitosis is halted will determine whether chromosomes appear with sister chromatids or not. Taken during mitosis – cells in metaphase. The chromosomes of an organism are arranged into homologous pairs according to size (with sex chromosomes shown last)
- The chromosomes are stained and photographed to generate a visual profile that is known as a karyogram– distinctive banding pattern
- Stain dividing cells→ placed on microscope → burst by pressing → micrograph
3.2.U10 Sex is determined by sex chromosomes and autosomes are chromosomes that do not determine sex.
- Outline the structure and function of the two human sex chromosomes.
- Outline gender determination by sex chromosomes.

Human sex determination occurs according to the X – Y system
- Females have two copies of the larger X chromosome
- Males have one X and one Y chromosome (and hence determine gender in offspring)
- The x chromosome is pretty big and has its centromere near the middle (women)
- y chromosome is much smaller and has its centromere near the end
- x has many genes that are important to both genders
- y only has a small number of genes, a small number of the y chromosomes has the same sequence of genes as a small part of the x chromosome, but the genes on the remainder of the y chromosome are not found on the x chromosome and are not needed for female development
- Fetus with 1 x and 1 y becomes a male, fetus with 2 x and 0 y becomes a female
3.2.A1 Cairns’ technique for measuring the length of DNA molecules by autoradiography.
- Describe Cairn’s technique for producing images of DNA molecules from E. coli.
- Outline conclusions drawn from the images produced using Cairn’s autoradiography technique.
Previously, chromosome length could only be measured while condensed during mitosis (very inaccurate due to supercoiling). Cairns used autoradiography to visualise the chromosomes whilst uncoiled, allowing for more accurate indications of length. By using tritiated uracil (3H-U), regions of active transcription can be identified within the uncoiled chromosome

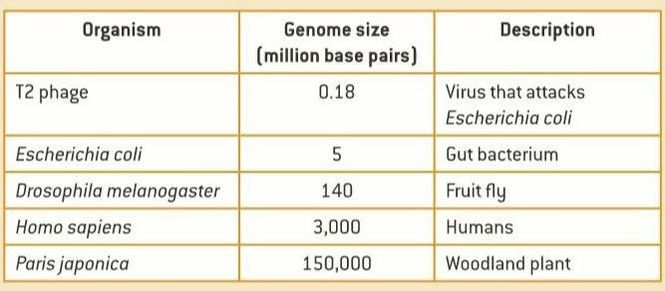
Genome size can vary greatly between organisms and is not a valid indicator of genetic complexity. The largest known genome is possessed by the canopy plant Paris japonica – 150 billion base pairs. The smallest known genome is possessed by the bacterium Carsonella ruddi – 160,000 base pairs.
As a general rule:
- Viruses and bacteria tend to have very small genomes
- Prokaryotes typically have smaller genomes than eukaryotes
- Sizes of plant genomes can vary dramatically due to the capacity for plant species to self-fertilise and become polyploid
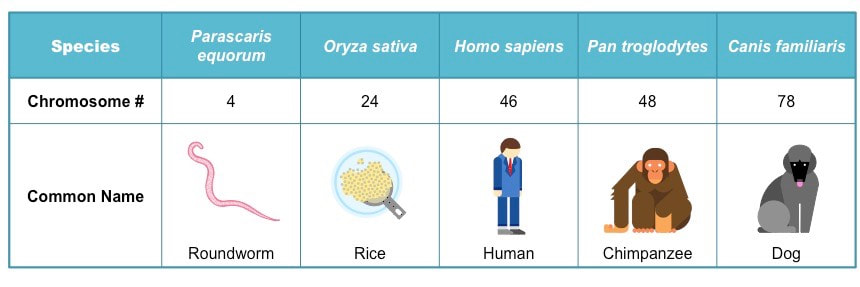
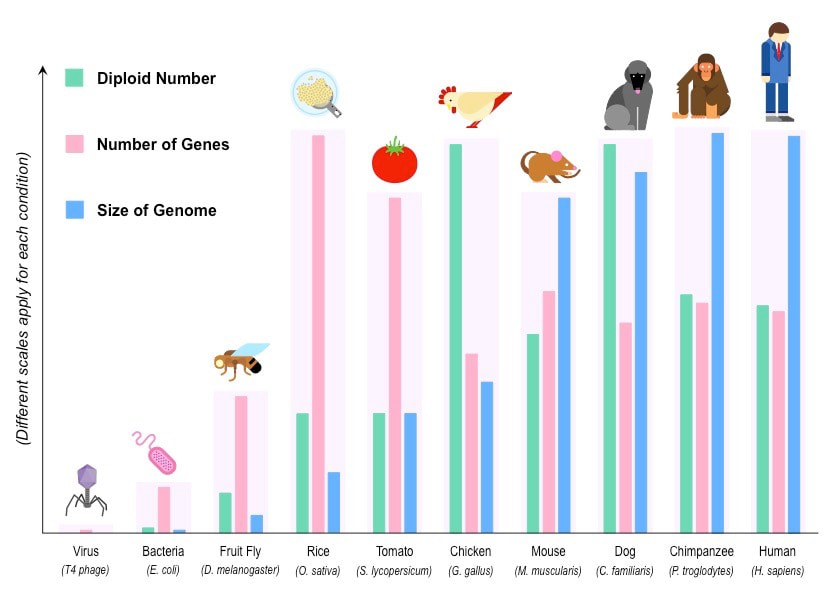
3.2.A3 Comparison of diploid chromosome numbers of Homo sapiens, Pan troglodytes, Canis familiaris, Oryza sativa, Parascaris equorum.
- State the minimum chromosome number in eukaryotes.
- Explain why the typical number of chromosomes in a species is always an even number.
- Explain why the chromosome number of a species does not indicate the number of genes in the species.
- Explain the relationship between the number of human and chimpanzee chromosomes.
Chromosome number does not provide a valid indication of genetic complexity, for instance:
- Tomatoes (Solanum lycopersicum) have 24 chromosomes and a genome size of 950 million bp, but possess ~32,000 genes
- Chickens (Gallus gallus) have 78 chromosomes and a genome size of 1.2 billion bp, but possess only ~17,000 genes
 |  |
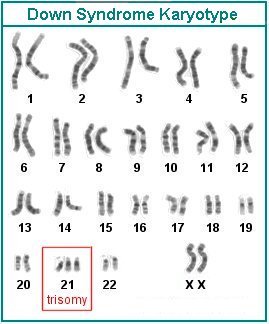
3.2.A4 Use of karyograms to deduce sex and diagnose Down syndrome in humans
- Distinguish between a karyogram and a karyotype.
- Deduce the sex of an individual given a karyogram.
- Describe the use of a karyogram to diagnose Down syndrome.
Karyotyping will typically occur prenatally and is used to:
- Determine the gender of the unborn child (via identification of the sex chromosomes)
- Test for chromosomal abnormalities (e.g. aneuploidies or translocations)
Down syndrome is a condition whereby the individual has three copies of chromosome 21. It is caused by a non-disjunction event in one of the parental gametes. The extra genetic material causes mental and physical delays in the way the child develops
The locus of a human gene and its polypeptide product can both be identified using a single online resource:
GenBank – a genetic database that serves as an annotated collection of DNA sequences
dentifying Gene Loci
GenBank can be used to identify the specific location of a gene on any given chromosome
To identify a specific gene locus:
- Change the search parameter from nucleotide to gene and type in the name of the gene of interest
- Choose the species of interest (i.e. Homo sapiens) and click on the link (under ‘Name / Gene ID’)
- Scroll to the ‘Genomic context’ section to determine the specific position of the gene locus
- A visual profile can be generated by clicking on ‘Map Viewer’ link and looking at the Ideogram on the left side
Identifying Polypeptide Products:
- GenBank can also be used to identify the polypeptide product of any given gene
To identify the polypeptide product of a gene:
- Change the search parameter from nucleotide to gene and type in the name of the gene of interest
- Choose the species of interest (i.e. Homo sapiens) and click on the link (under ‘Name / Gene ID’)
- The polypeptide product should be identified within the ‘Summary’ section