Basic Probability
The field of probability involves random processes. That is, processes whose results are determined by chance. The set of all possible outcomes is called the sample space, and an event is any subset of the sample space.
The probability of an event is the likelihood of it occurring and is represented as a number between 0 and 1 , inclusive. If the chance process is repeatable, the probability can be interpreted as the relative frequency with which the event will occur if the process is repeated many times.
If all of the outcomes in the sample space are equally like to occur, then the probability of an event \(E\) is the ratio of the number of outcomes in \(E\) to the number of outcomes in the sample space.
The completement of an event \(\mathrm{E}\), denoted \(\mathrm{E}^{\prime}\) or \(\mathrm{E}^{\mathrm{c}}\), is the event that consists of all outcomes that are not in \(\mathrm{E}\).
![]()
In many real-world situations, probabilities can be very difficult to calculate. When this happens, simulation can be used. Simulation is a technique in which random events are simulated in a way that matches as closely as possible the random process that gives rise to the probability. This is usually done by generating random numbers. The simulation can be repeated many times, and the simulated outcome examined for each repetition. The relative frequency of an event in this sequence of simulated outcomes is an estimate of the probability of the event.
Random Variables and Probability Distributions
A random variable is a variable whose numerical value depends on the outcome of a random experiment, so that it takes on different values with certain probabilities. A random variable is called discrete if it can take on finitely or countably many values. The sum of the probabilities of the possible values is always equal to 1 , since they represent all possible outcomes of the experiment.
A probability distribution represents the possible values of a random variable along with their respective probabilities. It is often represented as a table or graph, as in the following example:

The table shows a random variable \(X\) that can take on each of the values \(1,2,3,4\), and 5. It takes on the value 1 with probability 0.2 , the value 2 with probability 0.3 , and so on. Note that the sum of the probabilities is \(0.2+0.3+0.1+0.25+0.15=1\), as expected. The notation \(P(X=x)\) in the second row represents the probability of the random variable \((X)\) taking on one of its possible values \((x)\).
Sometimes it is beneficial to have a cumulative probability distribution, which shows the probabilities of all values of a random variable less than or equal to a given value.
The cumulative distribution for the example in the previous table is as follows:

A probability distribution has a mean and a standard deviation, just like a population. The mean, or expected value, of a discrete random variable \(\mathrm{X}\) is \(\mu_X=\sum x_i \cdot P\left(x_i\right)\). Its standard deviation is \(\sigma_X=\sqrt{\sum\left(x_i-\mu_X\right)^2 \cdot P\left(x_i\right)}\).
The probability that a visitor of the local botanical gardens walks through the rose garden is 0.65 , and the probability that a visitor meanders through the new meadow is 0.45 . The probability that a visitor does both activities on the same day is 0.32 . What is the probability that a visitor does at least one of the activities on a given day?
A. 0
B. 0.2925
C. 0.78
D. 0.22
E. 0.50
▶️Answer/Explanation
Explanation:
The correct answer is \(\mathrm{C}\). Let \(A\) be the event “walks through the rose garden” and \(B\) the event “meanders through the new meadow.” We must compute \(P(A \cup B)\). To do so, use the addition formula, as follows:
$
\begin{aligned}
& P(A \cup B)=P(A)+P(B)-P(A \cap B) \\
& =0.65+0.45-0.32=0.78
\end{aligned}
$
Choice A is incorrect because this event is far from impossible. Use the addition formula to compute the probability of the event “walks through rose garden OR meanders through new meadow.” Choice B is incorrect because when computing \(P(A \cup B)\), you multiplied the probabilities \(P(A)\) and \(P(B)\), which is incorrect; you must use the addition formula. Choice \(D\) is incorrect because this is the probability that a visitor does neither of these two activities on a given day. Choice \(\mathrm{E}\) is incorrect because there is not a 50-50 chance of this event occurring. You must use the addition formula to compute the probability of the event “walks through rose garden OR meanders through new meadow.”
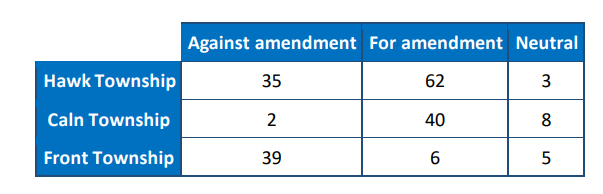
To study the relationship between township and support for a certain amendment concerning property tax, 200 registered voters were surveyed with the following results: