Question 1
Most-appropriate topic codes (IB Computer Science HL):
• Topic A.2 — The relational database model (Parts (a)(i), (a)(ii), (b), (c), (d), (e))
• Topic A.3 — Further aspects of database management (Part (f))
▶️ Answer/Explanation
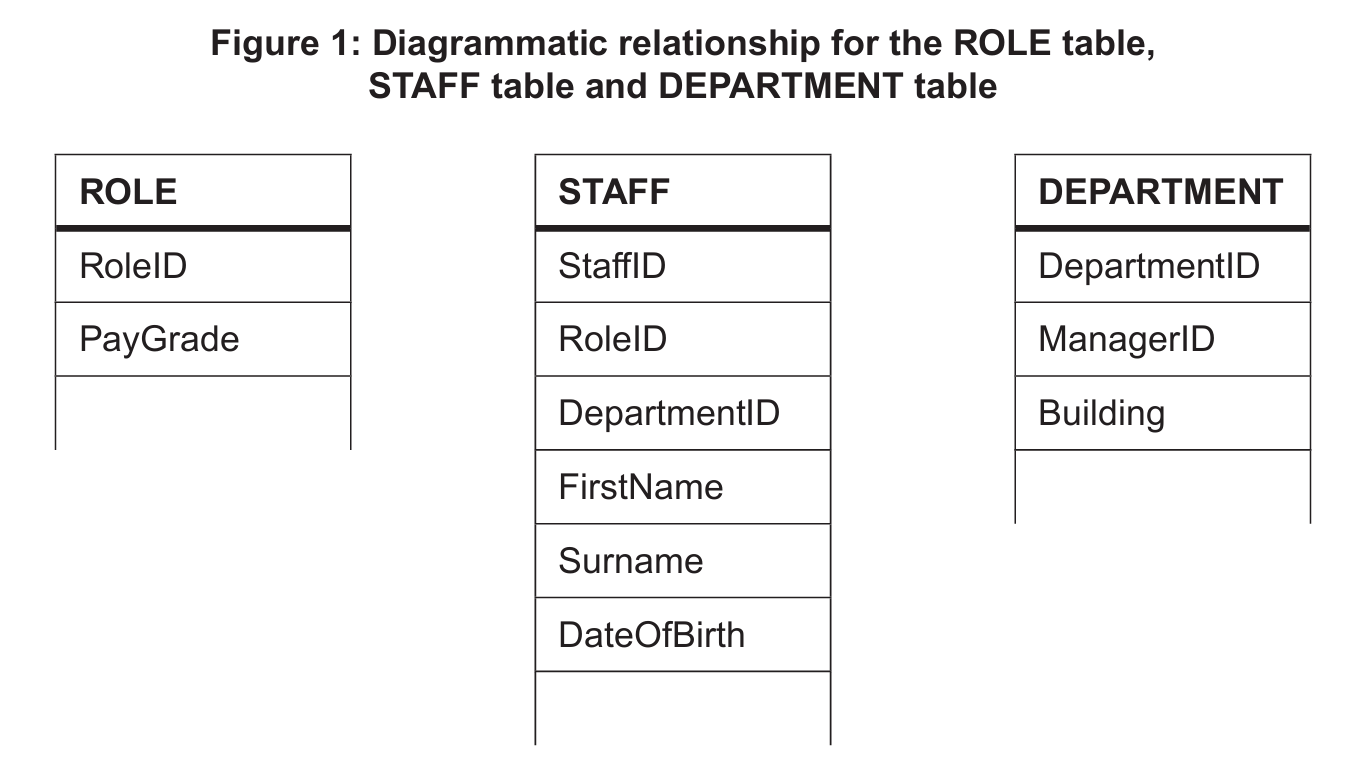
(a)(i)
For the correct answer:
StaffID
In any well-designed relational database table, the primary key serves as the unique identifier for each record, meaning every staff member will have their own distinct ID that will never repeat. So, looking at the structure of a STAFF table, the StaffID field is the most logical and standard choice to guarantee that each employee is uniquely identifiable.
(a)(ii)
For the correct answer:
RoleID or DepartmentID
A foreign key is a field in one table that links to the primary key in another table, creating a relationship between the two. In the STAFF table, the RoleID is needed to link each staff member to their specific job title in the ROLE table, and if there’s a direct link, a DepartmentID could similarly connect them to a department, making either a valid foreign key.
(b)
For the correct answer:
ROLE and STAFF: one to many
STAFF and DEPARTMENT: many to many
The relationship between ROLE and STAFF is one-to-many because a single role, like ‘nurse’, can be assigned to dozens of different staff members, but each staff member can hold only one role at a time. For STAFF and DEPARTMENT, it’s a many-to-many relationship since any staff member, such as a surgeon, can work in multiple departments, and each department will naturally contain many different staff members.
(c)
For the correct answer:
A query provides a virtual representation/filtered view of the database based on criteria set in the query.
A query is essentially a question you ask the database to retrieve specific information without seeing all the clutter. It allows you to filter, sort, and combine data dynamically, so instead of browsing thousands of records, the system instantly shows you only the names of staff matching a specific surname and pay grade, just like you requested.
(d)
For the correct answer:
SELECT STAFF.Firstname, STAFF.Surname, ROLE.PayGrade FROM STAFF INNER JOIN ROLE ON STAFF.RoleID = ROLE.RoleID WHERE STAFF.Surname = ‘Waters’ AND ROLE.PayGrade = 17
To get this result, you must first tell the database which columns you want (FirstName, Surname, PayGrade) by selecting them and then join the STAFF and ROLE tables together using the common key RoleID, because PayGrade is in the ROLE table. Finally, you set the filtering conditions to look for exactly ‘Waters’ in the Surname column and the number 17 in the PayGrade column, which narrows down the results.
(e)
For the correct answer:
The pay grade values are whole numbers.
An integer data type is a perfect fit here because pay grades like 17, 18, or 19 are always whole numbers without any fractions or decimals. Using an integer also keeps the database efficient, as it takes up less storage space than text and makes mathematical comparisons and sorting faster and more reliable.
(f)
For the correct answer:
The use of different levels of access/authorization. Meaning the minimum number of people have access to this data. For example, password protect/lock/restrict access to Role table.
Encrypting the stored data in the database. The data is scrambled/converted to cipher text (and cannot be understood without a key). For example, only the employees with the key can decrypt the data.
One effective way is implementing strict user authorization levels, which means designing the system so that a general administrative assistant can see basic contact details but is completely blocked from viewing sensitive salary or pay grade information, with access granted only to top-level HR managers. A second crucial method is encryption, where the database scrambles private data like pay grades and medical records into unreadable cipher text, so even if a hacker physically steals the hard drive, the information stays completely useless without the decryption key held by the hospital’s security team.
Question 2
Most-appropriate topic codes (IB Computer Science HL):
• Topic A.2 — The relational database model (Parts (a), (b), (c), (d), (e), (f))
▶️ Answer/Explanation
(a)
For the correct answer:
The conceptual schema is a high-level/least detailed representation of the database, identifying entities and relationships. The logical schema is more detailed, showing field names and developed from the conceptual schema.
The conceptual schema is like a rough sketch focusing on “what” data the system needs, identifying high-level entities like ‘Patient’ and ‘Doctor’ and their basic relationships without caring about database software. The logical schema takes that rough idea and formalises it into a precise blueprint, specifying every single field name, data type, and primary key—it’s the “how” stage that database developers can directly translate into a working system.
(b)
For the correct answer:
A DDL is used to specify the schema of a database, allowing you to define the tables, fields, and set datatypes (e.g., CREATE TABLE).
A Data Definition Language is crucial because it provides the actual coded commands to physically build the database structure you designed on paper into the computer. Without DDL commands like CREATE TABLE, your carefully planned data model would remain just an idea, as these statements are the only way to tell the database software to allocate space, create columns with specific data types, and enforce the relationships between your tables.
(c)
For the correct answer:
It helps to identify the entities/tables in the database to ensure they support the database’s purpose. Normalization during data modelling reduces data duplication, which reduces data anomalies and saves storage space.
Data modelling is used early on to visualise and organise all the information before any code is written, preventing a chaotic mess of redundant data. By carefully identifying entities and their attributes and then applying normalization rules, you eliminate harmful duplication—so a patient’s address gets stored once, not a hundred times—which prevents update anomalies where changing a piece of data in one place would leave old, incorrect versions in another.
(d)
For the correct answer:
Data validation is an automated process that ensures input meets data entry rules. Data verification is the checking of data to ensure it is the input intended. Using both techniques provides the optimal solution.
Validation alone isn’t enough because it only checks if data looks plausible, like a date of birth being in the past, but it can’t catch a user accidentally typing a correct-looking but wrong surname. Verification handles this human error, often by asking a person to double-check their input, so together, a system can automatically block impossible values while also catching slips of the finger, leading to truly accurate records for a hospital.
(e)
For the correct answer:
Integrity is maintained by no changes being made until the transaction is complete. If the transaction cannot be completed it is rolled back to the original state (Atomicity).
Consider transferring a patient’s record between departments—this isn’t a single action but a multi-step process, and the database must treat it as one unbreakable unit using atomicity. If any step fails—say the system crashes right after removing the patient from the old department but before adding them to the new one—the whole transaction must be rolled back automatically, returning the database to its initial, consistent state and preventing the patient’s record from being lost or orphaned.
(f)
For the correct answer:
Referential integrity is maintained by the connection between the primary key in one table and the foreign key in another, ensuring records are appropriately updated and preventing orphan records.
Relational integrity acts as a strict rulebook that prevents your database from falling into chaos, for example, by making it impossible to assign a staff member to a DepartmentID that doesn’t exist in the DEPARTMENT table. It also manages cascading updates—if a department’s ID code changes, the system automatically updates it for every single staff member linked to it, ensuring that all connections remain valid and that no one ends up assigned to a non-existent department.
Question 3
Most-appropriate topic codes (IB Computer Science HL):
• Topic A.2 — The relational database model (Parts (a)(i), (a)(ii), (b), (c))
▶️ Answer/Explanation
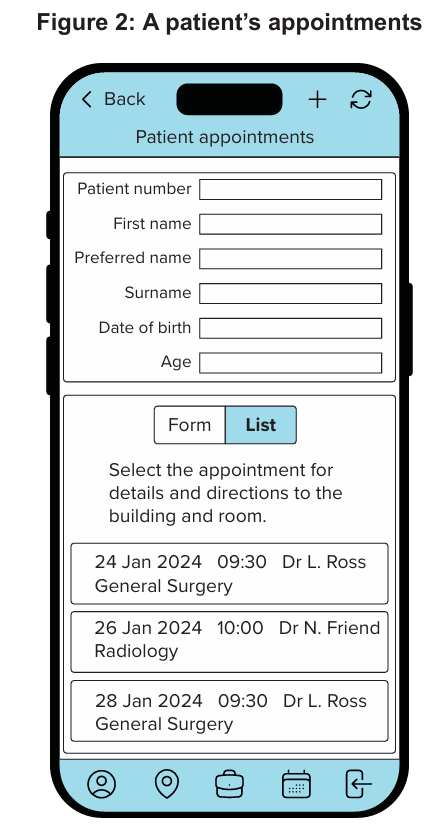
(a)(i)
For the correct answer:
A derived field is calculated using data that exists within the database, meaning the data does not have to be input or take up storage space.
Using a derived field like Age is a smart design choice because age changes constantly while a date of birth is fixed, so storing the age directly would require relentless manual updates. Instead, the database simply calculates it on the fly from the stored DateOfBirth whenever you run a query, guaranteeing the displayed age is always perfectly current without wasting any disk space.
(a)(ii)
For the correct answer:
Select Date of Birth from the patient table and subtract the year of the birth date from the current year to get the Age.
To dynamically compute a patient’s age, the system retrieves their stored DateOfBirth and mathematically finds the difference between that and today’s date. Behind the scenes, this usually involves a function like selecting `YEAR(CURDATE()) – YEAR(DateOfBirth)` from the table, which neatly outputs their age as a whole number without anyone having to do the mental arithmetic.
(b)
For the correct answer:
The prerequisite for 2NF is 1NF. The focus of 1NF is to eliminate repeating groups and ensure atomicity of data values, while the focus of 2NF is to ensure full functional dependency by removing partial dependencies.
First normal form is the foundational level where you make sure every cell contains just one value and there are no repeating columns, essentially cleaning up the messy spreadsheet layout into a proper table. Second normal form then builds on this by tackling only tables with composite primary keys, ensuring that every non-key attribute depends on the entire composite key, not just a part of it, which further reduces redundancy.
(c)
For the correct answer:
PATIENT (PatientID, FirstName, Surname, PreferredName, DateOfBirth)
DOCTOR (DoctorID, FirstName, Surname)
DEPARTMENT (DepartmentID, departmentName)
APPOINTMENT (PatientID*, DoctorID*, date, time, DepartmentID*)
To achieve a clean 3NF design, I need to split the appointment data into distinct entities because a patient and a doctor are separate real-world things with their own properties, and each department name should only be stored once. The central APPOINTMENT table ties everything together using foreign keys, so one appointment record simply points to the correct PatientID, DoctorID, and DepartmentID, while the date and time fields are fully dependent on that unique appointment event, eliminating any transitive dependencies.
Question 4
(g) Compare and contrast cluster analysis and association rules as methods of identifying patterns in data mining.
Most-appropriate topic codes (IB Computer Science HL):
• Topic A.4 — Further database models and database analysis (All parts (a) to (g))
▶️ Answer/Explanation
(a)
For the correct answer:
object-oriented; network
Apart from the classic relational model, an object-oriented database could be a powerful alternative because it stores data as objects, making it very intuitive for applications built with object-oriented programming languages. A network model is another option, which creates a more flexible web of connections between records, although it can become complex to navigate and manage compared to simpler relational tables.
(b)
For the correct answer:
Subject-oriented, integrated, time-variant, and non-volatile collection of data used in support of management decision making.
A data warehouse isn’t built for daily transaction processing like booking an appointment, but is a massive, centralised repository where data from multiple different systems is copied and organised for high-level analysis. It’s designed to be read-only, holding historical snapshots over long periods, so that managers can spot long-term trends without slowing down the operational databases.
(c)
For the correct answer:
The data required for a data warehouse may require the aggregation of data from multiple sources. The format of the data needs to be revised so it is in a consistent/standardized format before it is loaded into the data warehouse.
An ETL process is essential because each hospital in a region might have patient records in wildly different structures, with different codes for the same treatment or incompatible date formats. The ETL pipeline first extracts all this messy raw data, then transforms it by cleaning up errors, standardising naming conventions, and resolving duplicates, and finally loads this uniform, reliable dataset into the warehouse where it becomes truly useful for cross-hospital analytics.
(d)
For the correct answer:
The timestamping of data provides a recorded representation of data at a particular date/time. This allows data from different times to be compared and enables trends to be established.
Timestamping is what makes a data warehouse time-variant, essentially giving every piece of data a historical context so you know exactly when it was valid. Without it, comparing last year’s flu admissions to this year’s would be meaningless, but with a timestamp, analysts can slice the data by any period to build accurate trend lines and track seasonal patterns.
(e)
For the correct answer:
Data is extracted in real time from transaction systems, transformed and standardised, and then the system executes transactions in short intervals to load the data into the data warehouse.
For near-real-time updates, modern systems often use change data capture, where the moment a new record hits the operational database, a lightweight trigger grabs just that change and streams it through a mini-ETL pipeline. This freshly formatted data is then committed to the warehouse almost immediately, ensuring a dashboard showing current bed occupancy is only seconds behind the live hospital system.
(f)
For the correct answer:
Data is collected, standardized and transformed into numeric values, and statistical methods are used to build a model of normal behaviour to determine outliers.
Deviation detection is like a digital watchdog that learns what ‘normal’ patient activity looks like, from average wait times to typical prescription amounts, and then sounds the alarm when something falls outside these learned thresholds. For instance, if a single pharmacy suddenly orders ten times its usual quantity of a controlled drug, the system flags this outlier for immediate investigation by the health authority.
(g)
For the correct answer:
Cluster analysis groups abstract objects into classes of similar objects, while association determines relationships based on the co-occurrence of large sets of data items. Both techniques use unsupervised learning techniques.
Cluster analysis is like a sorting machine that puts patients into distinct groups based on measurable similarities, such as segmenting a population by common symptom patterns without any prior labels. Association rules work differently by mining for “if-then” patterns, like discovering that a diagnosis of diabetes very frequently occurs alongside a specific heart condition, and both are similar in that the computer finds these hidden patterns on its own without being told what to look for.
Question 5
- Maximum temperature
- Minimum temperature
- Mean temperature
- Day: 07:00 to 18:59 inclusive (12 hours)
- Night: 19:00 to 06:59 inclusive (12 hours)
- maximum temperature
- minimum temperature
- mean temperature
- mean night-time temperature.
Most-appropriate topic codes (IB Computer Science HL):
• Topic B.1 — The basic model (Part (a) (b) (d) (e))
• Topic B.3 — Visualization (Part (c))
• Topic B.2 — Simulations (Part (f))
▶️ Answer/Explanation
(a)
To calculate the mean daily maximum temperature, you need a variable to hold each day’s highest reading, such as `DailyMaximumTemperature`. You also need an accumulator variable, such as `TotalTemperature`, to sum these daily maximums before dividing by the count.
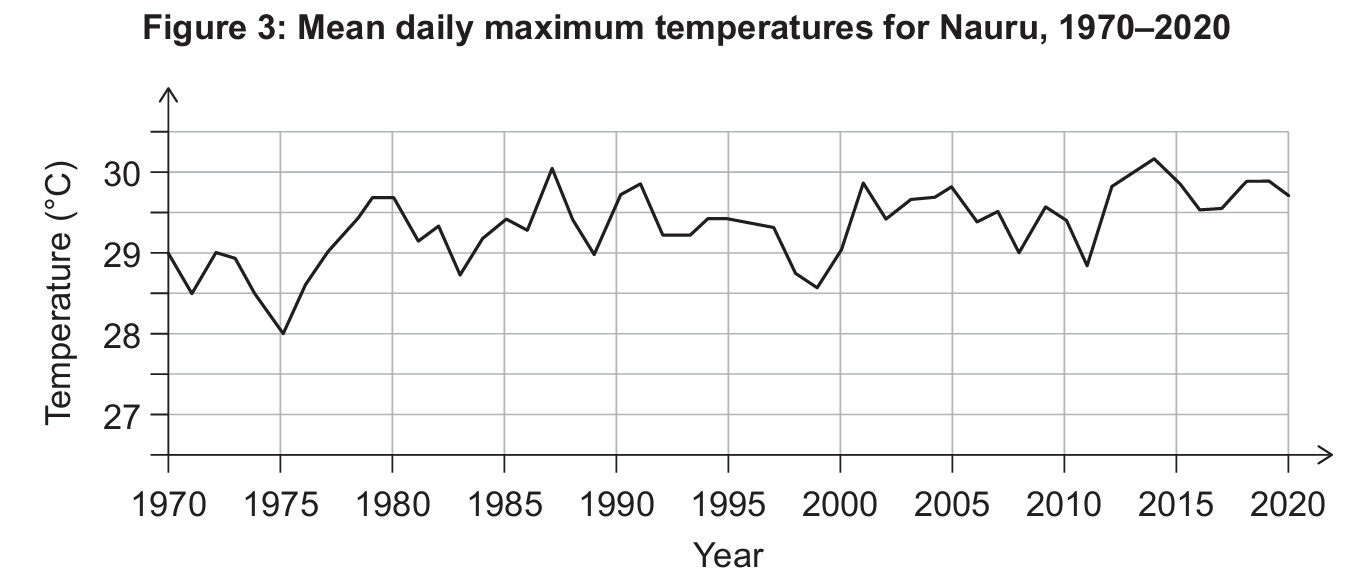
(b)
The steps to create the diagram would start with selecting the data cells for the mean daily maximum temperatures and the corresponding years. Next, you would choose the line graph chart type from the spreadsheet’s insert menu. Then, you would ensure the chart has the correct heading and finally label both axes appropriately, such as ‘Temperature (°C)’ for the y-axis and ‘Year’ for the x-axis.
(c)
The data is presented in graphical form firstly because displaying data visually allows trendlines to be identified, and this particular trend clearly displays the increase in mean daily temperatures over the time period shown. Secondly, complicated data like a long sequence of temperature readings is simply much easier for a person to understand and interpret quickly when it is displayed visually rather than as a table of raw numbers.
(d)
Collecting data once an hour, which results in 24 recordings over a day rather than the 1440 if collected every minute, will require significantly less data processing and less storage space. Furthermore, the minor temperature changes that might happen within each hour are negligible and should not affect the overall study of the climate, so hourly readings provide a sufficient and efficient dataset.
(e)
To store the data for a single day, you would first create two parallel one-dimensional arrays of size 24, perhaps named `TIME` and `TEMP`. You could then initialise the time array with the 24-hour clock format from 00:00, 01:00, and so on, up to 23:00 for the full day. Using a loop counter, you would loop 24 times, and during each iteration, you would store or display the current time element `TIME(N)` before inputting and storing the corresponding temperature reading in `TEMP(N)`.
(f)
The pseudocode algorithm would look like this: TOTAL = 0NIGHT_TOTAL = 0MIN = 1000MAX = -1000loop T from 0 to 23 NEXT = TEMP[T] TOTAL = TOTAL + NEXT if TIME[T] >= 19:00 AND TIME[T] < 07:00 then TOTAL_NIGHT = TOTAL_NIGHT + NEXT end if if NEXT < MIN then MIN = NEXT end if if NEXT > MAX then MAX = NEXT end ifend loopMEAN_TEMP = TOTAL / 24MEAN_TOTAL_NIGHT = TOTAL_NIGHT / 12
Question 6
Most-appropriate topic codes (IB Computer Science HL):
• Topic B.1 — The basic model (Part (a))
• Topic B.2 — Simulations (Parts (b), (c), (d))
▶️ Answer/Explanation
(a)
For the correct answer:
A model is a mathematical representation/abstraction of a real-life situation. A simulation is the running of a mathematical model over time on a computer.
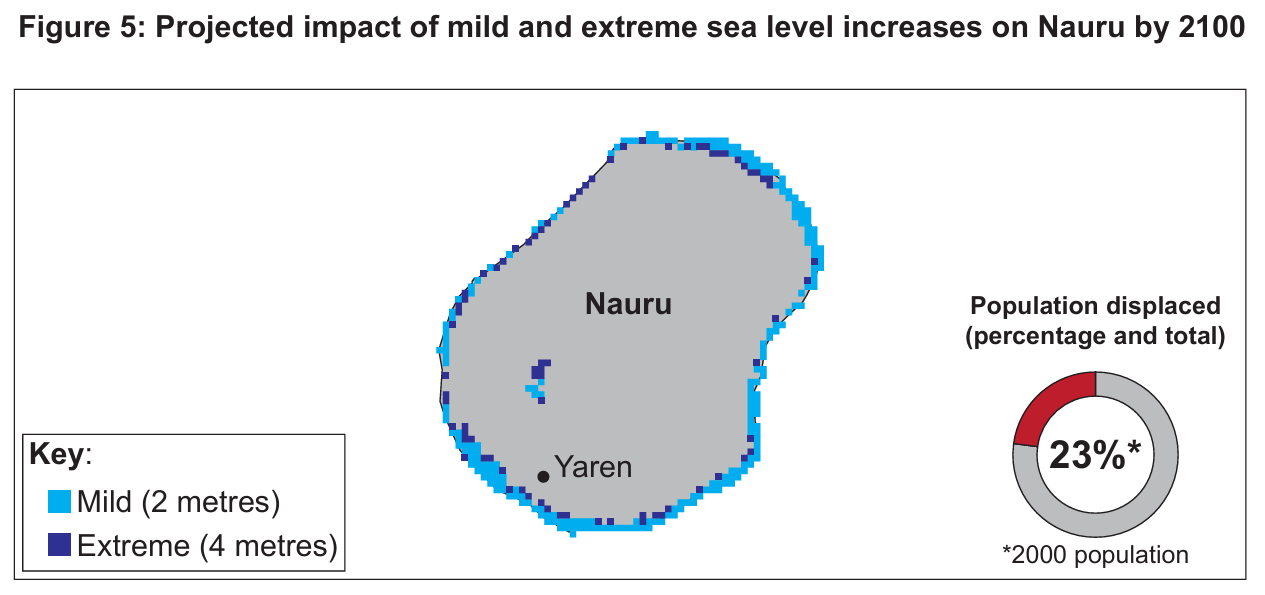
Think of a model as a static blueprint or a set of equations that describes the relationship between temperature and sea level—it’s the design on paper. A simulation breathes life into that model by executing it on a computer, stepping through time to show what actually might happen to Nauru’s coastline each year as temperatures rise.
(b)
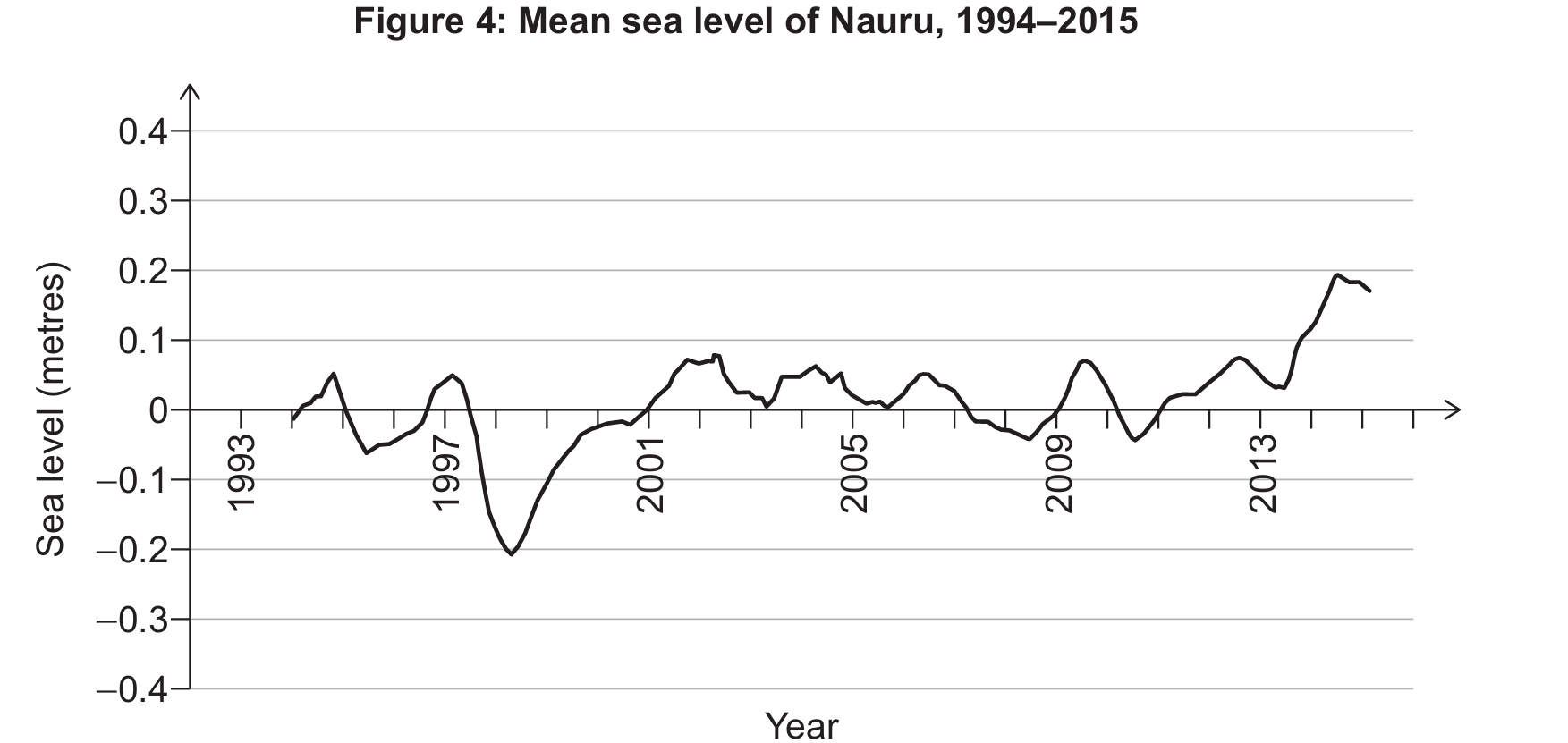
For the correct answer:
Collect / analyse data for any pair of temperature, sea level, and flooding; Suggest rules for the relationship; Check the suggested rules with actual data.
First, I would plot the historical temperature data against the sea level data to look for a mathematical correlation, perhaps a linear or exponential trend, that can be turned into a formula or a rule connecting the two. Once I have a candidate rule, I would feed historical temperature data into it and see if the predicted sea levels match what was actually observed, tweaking the rule until the output realistically mirrors the real-world records.
(c)
For the correct answer:
Find historical data not impacted by external factors; Input the observed data; Verify the simulation against the known results; Modify the model if necessary. This use of test cases will help to improve the model and therefore make the simulation more accurate.
An effective way to validate is to use a technique called back-testing, where I would run the simulation on a past decade of data that we already know the outcome for, like the years 2000–2010, and check if the simulation’s predicted flooding matches the historical records. If the simulation’s forecast for that period aligns closely with the real documented floods, I gain confidence in its reliability for predicting future scenarios, but if it’s off, I must go back and refine the underlying rules and algorithms until the test cases pass.
(d)
For the correct answer:
Advantages: It can produce measurable visual results and help predict flooding so communities can be prepared. Disadvantages: It is a crude solution only testing one or two factors and does not consider social or cultural factors.
A simulation gives government planners a powerful, risk-free sandbox to visualise “what-if” scenarios, such as testing if a proposed sea wall will save a village under the worst-case temperature rise by 2100, all without spending a dollar on concrete. On the downside, these decisions carry a heavy burden because a simulation is a radical simplification of reality and cannot model the deep cultural trauma of relocating a community from their ancestral land, yet a flawed simulation might be the only tool available, leading to decisions that technically work on paper but are socially devastating.
Question 7
Most-appropriate topic codes (IB Computer Science HL):
• Topic B.3 — Visualization (All parts (a) to (c))
▶️ Answer/Explanation
(a)
For the correct answer:
Visualization is a graphical representation of data.
A visualization transforms abstract numbers, like projected sea levels, into a graphical format that our eyes and brain can instantly process. Instead of reading a table of elevation figures, a colour-coded map of Nauru showing blue where the water will encroach makes the existential threat immediately obvious to anyone.
(b)
For the correct answer:
The image in memory is stored as a mathematical model. Images in memory are rendered to create a 3D visualization.
Inside the computer’s memory, a 3D scene of a flooded Nauru isn’t stored as a photograph but as a mathematical wireframe model defining the precise coordinates of every building and coastline. The graphics processor then takes that mathematical description and performs rendering, calculating lighting, shadows, and textures to convert it into the final 2D image on the screen that looks three-dimensional to us.
(c)
For the correct answer:
3D animation is very complex in terms of programming and requires a lot of time for processing/rendering. Rendering different layers and transitions requires a lot of RAM and may also require the use of secondary memory/GPU, which has the issue of a different processing speed. Therefore, 3D animation requires sufficient, fast primary and secondary memory.
Creating a smooth, fly-through animation of Nauru’s future flooding is extremely demanding because each frame of the film showing water creeping inland could take minutes or even hours to render, meaning a full five-minute animation might tie up a powerful computer for days. On the memory side, the system must hold the massive 3D mesh of the island’s terrain and all the high-resolution textures for sand, vegetation, and buildings in RAM simultaneously; if the working memory runs out, the process spills over onto much slower secondary storage, causing the rendering to grind to a frustrating crawl, so investing in fast GPU memory and plenty of it is non-negotiable for this kind of project.
Question 8

Most-appropriate topic codes (IB Computer Science HL):
• Topic B.4 — Communication modelling and simulation (Parts (a), (b), (c), (d), (e))
▶️ Answer/Explanation
(a)
For the correct answer:
Selection; Crossover; Mutation
A genetic algorithm starts by evaluating the current population against a fitness function and then selects the strongest candidates to be parents for the next generation, much like natural selection favouring the fittest. These selected solutions then undergo crossover, where parts of two good solutions are combined to create a potentially even better offspring, and finally, random mutation tweaks a small element to maintain diversity and prevent the algorithm from getting stuck at a local maximum.
(b)
For the correct answer:
Input layer; Hidden layer(s)
At its simplest, a neural network has an input layer that receives the raw data, which in the case of Go would be the state of every position on the board. Between the input and the final output, there are one or more hidden layers where the actual deep processing and pattern recognition magic happens through weighted connections.
(c)
For the correct answer:
Teach the rules for moves allowed in the game; Allow the neural network to predict moves based on previous moves; Play against human players of differing abilities; Play against itself; Use feedback loops to modify its decision making; Link back to the value network to judge how successful it has been.
Training begins by feeding the network thousands of historical professional Go games so it can learn fundamental strategies and common patterns of stone placement by imitation. The most powerful next step is self-play, where the AI plays millions of games against a copy of itself, and after each match, the value network judges who won, and the policy network updates its weights to make moves that led to victory more likely in the future, creating a continuous feedback loop of improvement.
(d)
For the correct answer:
Supervised learning uses labelled data to teach known outcomes based on given inputs, which can make the results more predictable. Unsupervised learning uses unlabelled data and the AI learns by looking for patterns and relationships on its own, which can lead to unpredictable outcomes.
If a Go neural network is trained using supervised learning with labelled historic games showing the correct winning move for each position, it will output safe and predictable strategies that closely mimic human grandmasters. In contrast, unsupervised learning just lets the network loose to find statistical structures in the data on its own, and the resulting output can be radically novel and creative, producing bizarre but effective strategies no human has ever considered, which is exactly the approach that led AlphaGo to invent its legendary “move 37.”
(e)
For the correct answer:
Pre-trained language models are pre-trained on large data sets and can be fine-tuned for specific tasks with a smaller set of labelled data. Contextual embedding represents words with a context, which greatly enhances semantic understanding and reduces ambiguity.
Advances like Transformer architectures and contextual embeddings mean a neural network no longer sees a word like “bank” as just a generic token but understands from the surrounding text whether it refers to a financial institution or a river side, resolving ambiguity that baffled older systems. This deep semantic grasp allows predictions in tasks like translation or question-answering to be far more accurate because the model has a genuine, context-aware understanding of language rather than just statistically matching words.
Question 9
Most-appropriate topic codes (IB Computer Science HL):
• Topic C.1 — Creating the web (All parts (a) to (d))
▶️ Answer/Explanation
(a)
For the correct answer:
The internet is a global network of inter-connected computers using internet protocols. The World Wide Web is a service on the internet, a collection of information and resources accessed via the internet using web browsers and protocols like HTTP.
The internet is the physical hardware infrastructure—a massive global network of cables, routers, and servers that connects billions of devices—while the World Wide Web is simply one of the many services that runs on top of that network, specifically the system of hyperlinked documents and resources accessed through a web browser using the HTTP protocol.
(b)
For the correct answer:
Protocol – https; Host – www.bbc.co.uk
A URL is packed with identifying information, starting with the protocol which tells the browser how to communicate with the server, which in this case is the secure HTTPS. Following that, the host or domain name uniquely identifies which specific computer on the vast internet hosts the files you want, here directing you to the BBC’s server.
(c)
For the correct answer:
FTP establishes two connections, one for control and one for data transfer; FTP facilitates the transfer of files efficiently between a client and a server.
FTP uses a clever dual-channel approach where one connection on port 21 handles the commands and login credentials, while a separate connection on port 20 is dedicated purely to shuttling the actual file data back and forth. This separation ensures that even while a large file is being transferred, you can still send control commands like abort or check the progress without clogging up the data pipeline.
(d)
For the correct answer:
Applies the appropriate protocols to enable communication with the web server; Provides a way to navigate to, access and fetch web pages using HTTP Request and Response; The data, typically written in a markup language such as HTML, is rendered to display web pages properly.
When you type a web address, the browser first acts as a translator, contacting a DNS server to convert the human-readable URL into a machine-friendly IP address before sending a structured HTTP GET request to the server. Once the server replies with the HTML, CSS, and JavaScript files, the browser switches roles and becomes an interpreter, parsing the raw code and meticulously laying out the text, images, and interactive elements on your screen in a process called rendering.
Question 10

if(isset(\$_FILES[‘CV’])){
\$errors = array();
\$file_name = \$_FILES[‘CV’][‘name’];
\$file_size = \$_FILES[‘CV’][‘size’];
\$file_tmp = \$_FILES[‘CV’][‘tmp_name’];
\$file_type = \$_FILES[‘CV’][‘type’];
\$file_ext = strtolower(end(explode(‘.’,\$_FILES[‘CV’][‘name’])));
\$extensions = array(“pdf”,”doc”,”docx”);
if(in_array(\$file_ext,\$extensions) === false){
\$errors[] = “This file extension not allowed”;
}
if(\$file_size > 2097152){
\$errors[] = “File size must be under 2 Mb”;
}
if(empty(\$errors) == true){
move_uploaded_file(\$file_tmp,”CV/”.\$file_name);
echo “Success”;
}else{
print_r(\$errors);
}
}
?>
<html>
<body>
<h1>Curriculum Vitae</h1>
<form action = “” method = “POST” enctype = “multipart/form-data”>
<input type = “file” name = “CV”/>
<input type = “submit”/>
</form>
</body>
</html>
Most-appropriate topic codes (IB Computer Science HL):
• Topic C.2 — Searching the web (Part (a), (b), (c), (d), (e))
• Topic C.1 — Creating the web (Parts (f), (g))
▶️ Answer/Explanation
(a)
A search engine is a software system, program, or application that searches the World Wide Web or a database for keywords that match the user’s specification. It can also apply filters such as date, usage rights, size, and currency if used.
(b)
A web crawler, also called a bot or spider, starts at a designated “seed” or starting page and reviews and categorises web pages based on criteria for the information searched for. It looks for keywords, content, hyperlinks, and meta tags, and then follows hyperlinks from page to page. The crawler can move through a site either depth-first or breadth-first, often copying part or all of the content of a visited page. This review can be stopped by rules set in a site’s robots.txt file, and the crawler continues this cycle, constantly updating the index with new or changed content.
(c)
Web crawlers look for keywords from the meta keywords and meta tags found in the meta description, title, and potentially the URL of the page. They then determine how many times the keywords appear in the body of the page. This information is used by the ranking algorithm as part of the ranking process, making keywords critically important for web indexing and supporting Search Engine Optimization (SEO).
(d)
An organization must weigh the short-term benefits against the long-term consequences. Black hat SEO involves manipulating search engine rules to gain a higher ranking, which can bring increased traffic, more visitors, and potentially increased revenue, directing users to content the developer wants them to see. Techniques include keyword stuffing, poor quality or duplicated content, hidden keywords, paid links, link farming, and cloaking. However, the disadvantages are severe: if detected, a search engine can penalize the site, resulting in a lower score, blacklisting, or being flagged as an unsafe site, causing reputational damage. Although initial ranking may improve, the long-term score can drop significantly. Furthermore, there are ethical issues concerning the provision of inaccurate or unreliable content. Ultimately, the long-term risk of being de-indexed and suffering reputational harm outweighs the temporary gain in traffic, making it an unsound strategy.
(e)
The deep web is a part of the World Wide Web that is not indexed by search engines and therefore is not discoverable by normal search engines; this includes databases and dynamic pages that require authentication. The surface web, in contrast, is indexed by common search engines and is therefore accessible to most users, being searchable by normal or common search engines like Google or Bing.
(f) (Output of the PHP code, for reference purpose.)
Curriculum Vitae
Four steps during the processing of this PHP code are: first, a user selects a file and clicks the submit button. Second, data is extracted from the file, including file size, file type, and name. Third, the file is checked against criteria in conditional statements for file extension (which must be pdf, doc, or docx) and for file size (which must not be greater than 2,097,152 bytes). Fourth, if there are errors, they are added to the error array; if the error array is empty, the file is uploaded and a success message is printed; otherwise, the errors from the array are printed.
(g)
When an organization chooses server-side processing, the processing of the script occurs on the web server rather than on the browser of the client. This results in a consistent result regardless of the processing capacity of the client device, and only the processed result is seen by the user. Crucially, the processing and underlying data are secure on the server, offering a more consistent experience for the end user and greater control for the site owner.
Question 11
Most-appropriate topic codes (IB Computer Science HL):
• Topic C.3 — Distributed approaches to the web (Parts (a), (b))
• Topic C.4 — The evolving web (Parts (c), (d))
▶️ Answer/Explanation
(a)
For the correct answer:
Lossless compression allows the compressed media to be reconstructed perfectly and completely, with no data deleted during the compression. It uses a shorthand version to replace repeating elements.
Instead of discarding any information like lossy compression does, lossless algorithms find and encode statistical patterns, such as replacing a long string of identical colour pixels with a short code saying “repeat this pixel value 500 times.” When the file is decompressed, every single bit of the original data is perfectly restored, so the video frame is mathematically identical to what was first captured.
(b)
For the correct answer:
A standard that is openly accessible and usable by anyone; Not owned by any governing body or private entity; Designed to ensure interoperability between systems and platforms.
An open standard like MP4 is essentially a public recipe book that any software developer can freely read and implement without paying royalties or asking permission from a controlling corporation. This open access guarantees that files created by one program will work flawlessly on any other device or platform, preventing the fragmentation and lock-in that happens with proprietary formats.
(c)
For the correct answer:
The decentralised web uses peer-to-peer networks where no single entity has control. Positive impacts: individual control means the user can allow or restrict information sharing, and ownership of the data remains with the user. Negative impacts: since there is no overall control, there is the ability to publish any information by anyone, making it harder for an individual to take down a page. Because data is stored across multiple nodes, there is a greater surface area for potential breaches or leaks. The right to be forgotten becomes nearly impossible to enforce on a truly decentralised system.
On the one hand, a decentralised architecture liberates individuals from surveillance by giant tech companies, giving them true ownership and cryptographic control over their personal data without a middleman mining it for profit. However, this same lack of a central authority becomes a privacy nightmare when harmful content or personal secrets are leaked, because there is no company headquarters to send a takedown request to; the data is replicated across countless independent nodes worldwide, making a right to be forgotten practically unenforceable under current law.
(d)
For the correct answer:
Economic and operational efficiency: no need to develop physical software packages or large infrastructure; cloud storage protects data from loss. Accessibility and scalability: users from any region can access the platform without physical distribution; widespread smartphone and internet access increases the user base.
The advent of cloud computing and SaaS meant a tiny startup like Xero in New Zealand didn’t need to build a global network of offices and distribution channels; it could simply launch a website and instantly offer its accounting service to anyone with a web browser. Combined with digital marketing and secure online payment gateways, the web effectively erased the geographical and logistical barriers that would have buried a small company just two decades earlier, allowing them to compete on a level playing field with global giants.
Question 12
- n is the number of nodes
- effect is the number of edges.
Most-appropriate topic codes (IB Computer Science HL):
• Topic C.5 — Analysing the web (All parts (a) to (c))
▶️ Answer/Explanation
(a)(i)
For the correct answer:
A node is a point in the network where connections intersect or branch out, usually represented as a website or page, sometimes called a vertex.
In the web graph, each individual webpage like a news article or a blog post is represented as a single node, forming the fundamental dot in the bowtie diagram that hyperlinks can point to or originate from.
(a)(ii)
For the correct answer:
An edge is the link or connection between nodes, representing a hyperlink from one page to another.
Every clickable hyperlink on a webpage is modelled as a directed edge in the graph, connecting the source node to the destination node and capturing the directional nature of web navigation.
(b)
For the correct answer:
The Strongly Connected Core (SCC) is a subset of nodes where each node is connected to every other node through one or more direct links.
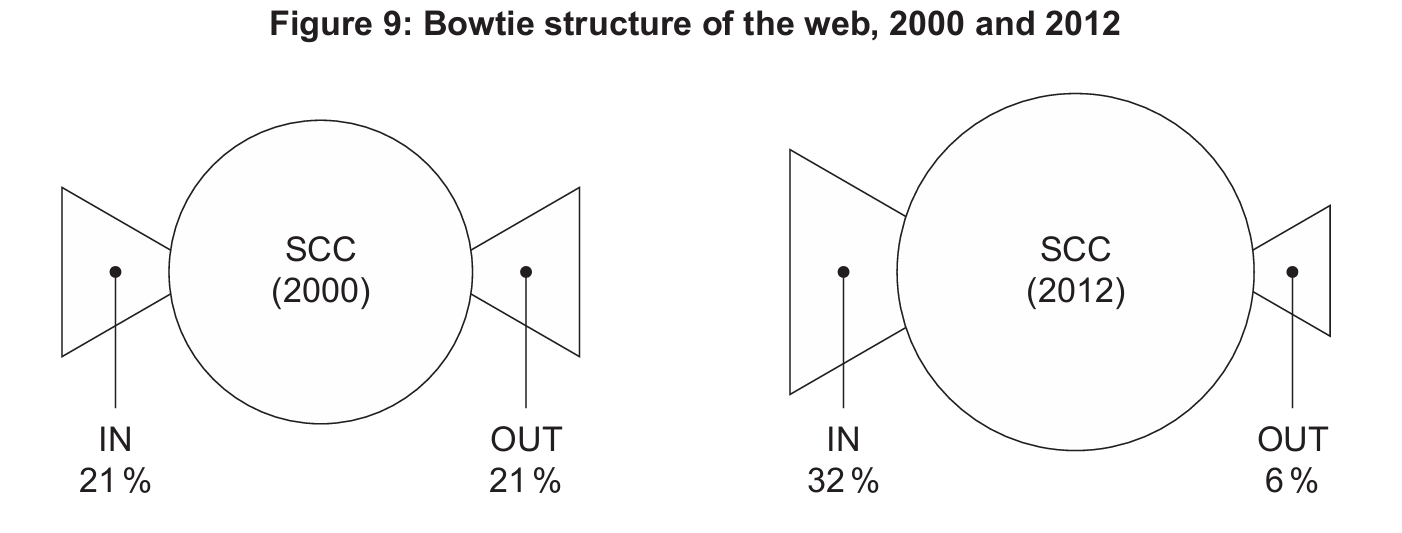
The SCC sits at the heart of the bowtie, representing the dense central hub of the web where you can navigate from any page to any other just by clicking links, and comparing the 2000 and 2012 crawls shows the diameter of this core grew significantly, indicating the central hub became more tightly interconnected over that decade.
(c)
For the correct answer:
Metcalfe’s Law assumes full connectivity between all nodes, but the bowtie structure shows only the SCC is fully connected while the IN and OUT components are not connected to each other or the entire network. Therefore, Metcalfe’s Law overestimates overall connectedness because it does not account for directionality or the disconnected parts of the web.
Using Metcalfe’s elegant formula \(n(n-1)/2\) to model web connectedness would falsely assume every webpage can directly reach every other, but the bowtie model visually proves large OUT and IN components exist in relative isolation, meaning the law drastically overestimates the true navigable structure of the internet.
Question 13
(b) Outline two reasons why ontologies rather than folksonomies will enable computer systems like search engines to work in cooperation with people.
(c) Distinguish between ambient intelligence and collective intelligence.
(d) To what extent does the use of collective intelligence contribute to the development and evolution of search engines?
Most-appropriate topic codes (IB Computer Science HL):
• Topic C.6 — The intelligent web (All parts (a) to (d))
▶️ Answer/Explanation
(a)
For the correct answer:
The semantic web is developed using well-structured data and tags/metadata in such a way that it can be read directly by computers. The Semantic Web aims to allow different systems, platforms, and applications to understand and share data meaningfully.
The core vision of the Semantic Web is to move from a web of simple linked documents to a web of linked data with rich, machine-readable meaning, where a computer can understand that a string of numbers on a page isn’t just text but a specific date, price, or location. This enables intelligent agents to autonomously integrate information across different websites, so your calendar could automatically cross-reference a concert listing with your schedule and book tickets without you lifting a finger.
(b)
For the correct answer:
Ontologies use a common formal language, which allows a more consistent and deeper understanding of the relationships. The formal structure better suits computer systems than the informal structure of folksonomy, reducing ambiguity and improving search.
An ontology defines a strict, shared vocabulary with explicit rules for how concepts relate to each other, so a machine knows with certainty that “Canis lupus” and “gray wolf” refer to the exact same biological entity. A folksonomy, like user-generated hashtags on social media, is inherently chaotic and ambiguous—the tag #apple could refer to the fruit, the technology company, or a record label—and this informal messiness makes it impossible for a search engine to reliably infer precise meaning and cooperate with a human’s true intent.
(c)
For the correct answer:
Ambient intelligence is an electronic system that is sensitive and responsive to the presence of people. Collective intelligence is group intelligence where collaborations and consensus contribute to understanding, such as social media or crowdsourcing.
Ambient intelligence is all about the environment becoming smart and adaptive around an individual, like a room that dims the lights and plays your favourite music the moment you walk in based on biometric sensors and learned preferences, focusing entirely on that one person’s immediate context. Collective intelligence is the opposite concept scaled up, where the aggregated, messy contributions of thousands or millions of people—such as the combined editing history of a Wikipedia article or the aggregated clickstream data of all Google users—create an intellectual output that is far smarter and more accurate than any single expert could produce alone.
(d)
For the correct answer:
Collective intelligence contributes fundamentally and extensively to the evolution of search engines. Modern search engines operate by harvesting the collective intelligence of all users through implicit feedback loops.
Google’s foundational PageRank algorithm is itself a form of collective intelligence, determining a page’s authority not by a human editor’s judgment but by mathematically analysing the collective linking behaviour of millions of independent webmasters, which is a form of crowd-sourced voting. Beyond this, every time a user types a query and then clicks one result while ignoring the other nine blue links, that action feeds back into the machine learning models, making the search engine smarter for everyone else, and techniques like analysing aggregated search logs to correct spelling mistakes or predict trending queries mean the system is continuously refined by the hive mind of its entire global user base on a minute-by-minute basis.
Question 14
Artist and Artwork:public class Artist {
private String artistName; // name of the artist
private String artistLocation; // current location of the artist
private int noOfArtworks; // number of works of art the artist has
// stored in the array theArtworks
private Artwork [] theArtworks; // details of the works of art produced
// by the artist
public Artist(String artistName, String artistLocation) {
this.artistName = artistName;
this.artistLocation = artistLocation;
noOfArtworks = 0;
theArtworks = new Artwork [100]; // an artist has a maximum of 100
// artworks
}
public String getName() { return artistName; }
public String getLocation() { return artistLocation; }
public Artwork getArtwork(int x) { return theArtworks[x]; }
public void addArtwork(Artwork x) {
theArtworks[noOfArtworks] = x;
noOfArtworks = noOfArtworks + 1;
}
public double commissionToPay()
// code missing
}
public Artwork[] sortArt() {
// code missing
}
} // end of class Artistpublic class Artwork {
private String artworkTitle; // name of the artwork
private int artworkPrice; // price of artwork
private boolean isSold; // if the artwork has been sold or not
public Artwork(String artworkTitle, int artworkPrice) {
this.artworkTitle = artworkTitle;
this.artworkPrice = artworkPrice;
isSold = false; // default value is not sold
}
public String getArtworkTitle(){ return artworkTitle; }
public void isSold(){ isSold = true; }
} // end of class ArtworkArtist class and Artwork class. Artist and Artwork classes, outline the use of the modifier private. Artist class.Most-appropriate topic codes (IB Computer Science HL):
• Topic D.1 — Objects as a programming concept (Part (a), (b), (d), (f))
• Topic D.2 — Features of OOP (Part (e))
• Topic D.3 — Program development (Part (c))
▶️ Answer/Explanation
(a)
For the correct answer:
Aggregation / “has a” relationship.
The Artist class contains an array of Artwork objects (private Artwork [] theArtworks;). This is an aggregation relationship because an Artist “has a” collection of Artwork objects. The Artwork objects can exist independently of the Artist, though they are stored within the Artist class.
(b)
For the correct answer (any two):
Instantiation is the process of creating a new object of the class;
Involves calling the constructor of the class;
Object’s attributes are initialized / object gets memory during instantiation.
Instantiation is the mechanism by which a concrete object is created from a class blueprint. When the new keyword is used in Java (e.g., new Artist(...)), memory is allocated for the object on the heap, and the constructor is invoked to initialize its instance variables to their starting values. For example, in the Artist constructor, noOfArtworks is set to 0 and the theArtworks array is initialized with space for 100 references.
(c)
For the correct answer:
Artist A = new Artist("Thomas Lucas", "Ireland");The code must include: (1) the declaration of a variable of type Artist (e.g., Artist A — accept any variable name), (2) the new keyword to allocate memory, (3) a call to the Artist constructor with the correct two String arguments in the correct order: the artist’s name first ("Thomas Lucas"), then the artist’s location ("Ireland"). The constructor signature is Artist(String artistName, String artistLocation), so the arguments are mapped accordingly.
(d)
For the correct answer (both points):
Private attributes cannot be accessed outside the class / private attributes need accessor/mutator methods to be accessed/modified;
Using the reference from the Artist/Artwork class.
The modifier private enforces encapsulation by restricting direct access to instance variables from code outside the class. For example, in the Artwork class, the attribute artworkTitle is declared private. To access its value from the Artist class, the programmer must use the public accessor method getArtworkTitle(). This protects data integrity by preventing unauthorized or unintended modifications to the internal state of objects.
(e)
For the correct answer (any two clusters of advantage + expansion):
Easier / faster to debug: Because there are far fewer mistakes in the smaller/individual modules. When a program is divided into separate, self-contained modules, isolating the source of an error becomes significantly simpler, reducing debugging time.
Speedier / faster completion of the project: Because different teams work on different modules simultaneously. Modularity enables parallel development, where multiple programmers can independently develop, test, and integrate separate modules, accelerating the overall project timeline.
Collaborative / qualitative development: As teams (programmers) with expertise work on specific modules. Specialists can focus on modules matching their skills (e.g., GUI, database, logic), leading to higher-quality code in each component.
Facilitates reusability of the code: As the existing modules can be reused across other modules or future projects. Well-designed, independent modules can be imported and utilized in different programs, saving development effort.
Improves code readability / organisation: Smaller manageable modules leading to better logical organization. Breaking down a complex system into cohesive modules with clear responsibilities makes the overall codebase easier to navigate and understand.
Reduces the coupling effect: Leading to easier/faster maintenance of a module without affecting others. When modules have minimal dependencies, changes or fixes in one module are less likely to cause cascading errors in unrelated parts of the system.
(f)
For the correct answer:
| Artist |
| – artistName: String – artistLocation: String – noOfArtworks: int – theArtworks[]: Artwork |
| + Artist(artistName: String, artistLocation: String) + getName(): String + getLocation(): String + getArtwork(x: int): Artwork + addArtwork(x: Artwork): void + commissionToPay(): double + sortArt(): Artwork[] |
The UML class diagram requires: (1) a box divided into three compartments (class name, attributes, methods); (2) the class name Artist in the top compartment; (3) the four private attributes (artistName: String, artistLocation: String, noOfArtworks: int, theArtworks[]: Artwork) preceded by a minus sign (-) in the middle compartment; (4) the public methods (constructor, accessors, mutators, and other methods) preceded by a plus sign (+) with their parameter types and return types in the bottom compartment. At least one method (constructor, accessor, mutator, or other) must be shown to demonstrate the correct syntax. The - and + symbols (or the words private/public) must be used correctly to indicate access levels. The parameters in the constructor and methods should indicate the data types (String, int, Artwork) and return types (String, Artwork, void, double, Artwork[]).
Question 15
Painting, Sculpture, and Performance, are created for the three different categories of artwork.typeOfPaint belongs to Painting. It holds the name of the type of paint used.weight belongs to Sculpture. It holds the weight of a sculpture.needForSound belongs to Performance. It states whether sound is needed for the performance.typeOfPaint;weight; needForSound. Painting, Sculpture, and Performance). Artist has been declared in the main class, and objects are added using the following code:theArtists[0] = new Artist("Nishan Nathan", "Italy");
theArtists[1] = new Artist("Saskia Anna", "Egypt");
theArtists[2] = new Artist("Kate Matherson", "USA");isSold in the Artwork object needs to be set to true when an artwork has been sold.Sold(String artistName, String artworkTitle), that will loop through the theArtists array and set the isSold variable to true.theArtworks array.Most-appropriate topic codes (IB Computer Science HL):
• Topic D.1 — Objects as a programming concept (Part (a))
• Topic D.2 — Features of OOP (Part (b)(i), (b)(ii))
• Topic D.3 — Program development (Part (c))
▶️ Answer/Explanation
(a)(i)
For the correct answer:String
The variable typeOfPaint holds the name of the type of paint used (e.g., “oil”, “acrylic”, “watercolour”). Since names are textual data consisting of a sequence of characters, the String data type is the appropriate choice. Strings are objects in Java that store sequences of Unicode characters.
(a)(ii)
For the correct answer:int / float / double
The variable weight holds a numerical measurement representing the weight of a sculpture. Depending on the precision required, any numeric data type is acceptable: int for whole-number weights (e.g., kilograms rounded to the nearest integer), or float/double for weights requiring decimal precision (e.g., 15.5 kg).
(a)(iii)
For the correct answer:boolean
The variable needForSound states whether sound is needed for the performance — a question that has only two possible answers: yes or no, true or false. The boolean data type is designed precisely for this purpose, storing logical values of true or false.
(b)(i)
For the correct answer (any two clusters of advantage + expansion):
Reuse of code: Through inheritance, subclasses can use methods of the superclass / less code needs to be written / saves time in coding. Rather than redefining common attributes and behaviours in every subclass, the subclasses inherit them from a shared superclass, eliminating redundancy.
Code flexibility/extensibility: Extending the parent’s actions and data without redefining them (polymorphism). New functionality can be added to existing class hierarchies by extending a superclass and adding specialised features in the subclass, making the system adaptable to changing requirements.
Child class redefines the base class methods (Overriding): To provide a different functionality to the existing method of the parent class. A subclass can override an inherited method to provide behaviour specific to that subclass, while still maintaining a common interface with sibling classes.
Easy to debug: As the existing code (base class methods) are already tested / less code needs to be debugged. When the superclass has been thoroughly tested, bugs can be isolated to the subclass-specific additions, narrowing the search for errors.
Easier to maintain: As the changes in the parent class are automatically reflected in the child class. When a shared behaviour needs updating, modifying it once in the superclass propagates the change to all subclasses, reducing maintenance effort and the risk of inconsistent updates.
(b)(ii)
For the correct answer (all three points):
All the common attributes related to the artworks could be in a superclass (Artwork);
Specific attributes related to the different types of artwork could be added to the subclasses (Painting / Sculpture / Performance);
When instantiating an artwork, the specific artwork would be chosen rather than “Artwork“.
The three classes share common attributes such as artworkTitle, artworkPrice, and isSold. Using inheritance, these common attributes and associated methods (e.g., getArtworkTitle(), isSold()) would be defined once in a superclass — the existing Artwork class. Each of the three new classes (Painting, Sculpture, Performance) would then extend Artwork using the keyword extends, automatically acquiring these common features. The specific variables unique to each category (typeOfPaint, weight, needForSound) would be declared only in the appropriate subclass. When creating an object, the programmer would instantiate the specific subclass (e.g., new Painting(...)) rather than the generic Artwork class, ensuring the object possesses both the inherited common attributes and its own specialised attributes.
(c)
For the correct answer:
public void Sold(String artistName, String artworkTitle) {
for (int i = 0; i < theArtists.length; i++) {
if(theArtists[i].getName().equals(artistName)) {
for (int x = 0; x < theArtists[i].getNoOfArtworks(); x++) {
if(theArtists[i].getArtwork(x).getArtworkTitle().equals(artworkTitle)) {
theArtists[i].getArtwork(x).isSold();
}
}
}
}
}Alternative solution using boolean flag:
public void Sold(String artistName, String artworkTitle) {
boolean found = false;
int i = 0;
while(i < theArtists.length && found == false) {
if(theArtists[i].getName().equals(artistName)) {
int j = 0;
while(j < theArtists[i].getNoOfArtworks() && found == false) {
if(theArtists[i].getArtwork(j).getArtworkTitle().equals(artworkTitle)) {
theArtists[i].getArtwork(j).isSold();
found = true;
}
j++;
}
}
i++;
}
}The method requires: (1) a loop to iterate through the theArtists array; (2) a comparison to find the matching artistName using .equals(); (3) a nested loop to iterate through the artist’s theArtworks array; (4) a comparison to find the matching artworkTitle; (5) a call to isSold() to set the artwork as sold; (6) correct use of accessor methods such as getName(), getArtwork(), and getArtworkTitle(). An optional boolean flag (found) can be used to exit the loops early once the artwork is found, improving efficiency. The method signature must match exactly: public void Sold(String artistName, String artworkTitle).
Question 16
noOfArtworks for an artist.sortArt() in the Artist class that will find the five most expensive artworks for a given artist. You must make use of the selection sort algorithm.commissionToPay calculates the commission to be paid by an artist on all sold artworks.commissionToPay that will calculate and return the amount of commission to be paid by the artist to the shop.Most-appropriate topic codes (IB Computer Science HL ):
• Topic D.4 — Advanced program development (Part (a) to (c))
• Topic D.3 — Program development (Part (d))
▶️ Answer/Explanation
(a) 0
(b)
public Artwork [] sortArt() {
for (int i = 0; i < noOfArtworks-1; i++) {
int max_index = i;
for (int j = i+1; j < noOfArtworks; j++) {
if(theArtworks[j].getArtworkPrice() > theArtworks[max_index].getArtworkPrice()) {
max_index = j;
}
}
Artwork temp = theArtworks[max_index];
theArtworks[max_index] = theArtworks[i];
theArtworks[i] = temp;
}
Artwork [] expensive = new Artwork[5];
for (int i = 0; i < 5; i++) {
expensive[i] = theArtworks[i];
}
return expensive;
}The selection sort repeatedly finds the maximum price element from the unsorted portion and swaps it to the front. After sorting in descending order, the first five elements are the most expensive artworks.
(c)
public double commissionToPay() {
double total = 0;
double commission = 0;
for (int i = 0; i < noOfArtworks; i++) {
if (theArtworks[i].getIsSold() == true) {
total = total + theArtworks[i].getArtworkPrice();
}
}
commission = total * 0.15;
return commission;
}The loop iterates through all artworks, summing the prices of those where isSold is true. The total is then multiplied by \(0.15\) (i.e., \(15\%\)) to calculate the commission.
(d)
Unicode has \(2^{16}\) (about 64,000) characters / more bits than ASCII;
Which enables characters from different alphabets/languages to be used/stored, promoting internationalization.
Question 17
Customer class:public class Customer {
private String customerName;
private String customerAddress;
private int maximumBudget;
public Customer (String customerName, String customerAddress, int maximumBudget()) {
this.customerName = customerName;
this.customerAddress = customerAddress;
this.maximumBudget = maximumBudget;
public int getMaximumBudget(){ return maximumBudget; }
// additional accessor and mutator methods exist but are not shown
public String toString() {
return "Name:" + customerName + ", Address:" + customerAddress + ", Maximum Budget:" + maximumBudget;
}
} // end of class Customer
int.public int countRecursive (LinkedList <Customer> customerList, int max, int n), that returns the number of customers who have a maximum budget greater than the price of this artwork.Most-appropriate topic codes (IB Computer Science HL):
• Topic D.4 — Advanced program development (Part (a) to (d))
▶️ Answer/Explanation
(a)
Library collections offer built-in methods to add, remove, and access elements; reducing manual coding and making development faster and less prone to errors.
OR
Using library collections leads to cleaner, more readable code than manual array handling; making it easier for others to understand and maintain.
OR
Library collections offer methods like size(), isEmpty(), get(), remove(); that simplify common tasks and help reduce logical errors.
(b)
Iterate through linked list, starting at the head pointer;
Using compareTo(), identify the correct position until a larger node is found or null;
Set the next of the new node to the next of the previous node;
Set the next of the previous node to the new node;
Update the head pointer if the new node is to be added at the start of the list.
The algorithm traverses the linked list node by node, comparing the customer name of each existing node with the new customer’s name using compareTo(), which returns a value based on lexicographic ordering. Once the correct alphabetical position is located (when a node with a “larger” name is found, or the end of the list is reached), the new node is inserted by adjusting the next pointers of the surrounding nodes.
(c)(i)
Recursion is a technique/process where a method calls itself; each call involves updated parameters; until it reaches the base case.
(c)(ii)
public int countRecursive (LinkedList <Customer> customerList, int max, int n) {
// Base case: size of list = 0
if (n == 0) {
return 0;
}
else if (customerList.get(n-1).getMaximumBudget() > max) {
return 1 + countRecursive(customerList, max, n-1);
}
else {
return countRecursive(customerList, max, n-1);
}
}The base case n == 0 returns 0 when there are no more customers to check. The parameter max represents the artwork price (\(\$40000\)). Each recursive call checks the customer at index n-1: if their maximumBudget exceeds max, the method returns \(1 +\) the result of the recursive call on the remaining list; otherwise, it simply returns the recursive result without incrementing. The value of n decreases by 1 each call, moving backwards through the list until n = 0.
(c)(iii)
Memory Usage: Recursive algorithms use the call stack for each call, leading to excessive memory usage; this is inefficient for simple tasks like counting through a list, especially when the list is large.
Processing Overhead: Each recursive call adds overhead due to repeated function calls and return handling; an iterative loop processes the same task more efficiently with lower runtime cost.
Complexity: The task of counting elements based on a simple condition does not require backtracking or divide-and-conquer; a linear loop with a counter is easier to write, read, and debug for this scenario.
Stack Overflow: Extensive recursion can exceed the maximum call stack size, especially with large linked lists; this can cause runtime errors, which are avoidable with iteration.
(d)
Naming conventions improve code readability/maintainability; consistent naming helps developers understand the purpose of variables/methods/classes easily.
OR
Faster collaboration; when team members follow the same conventions, it reduces confusion and makes code integration smoother.
In the Customer class, for example, the variables customerName, customerAddress, and maximumBudget use camelCase naming, and the accessor method getMaximumBudget() follows the standard get prefix convention, making the code self-documenting and predictable for other programmers.