Genes and Polypeptides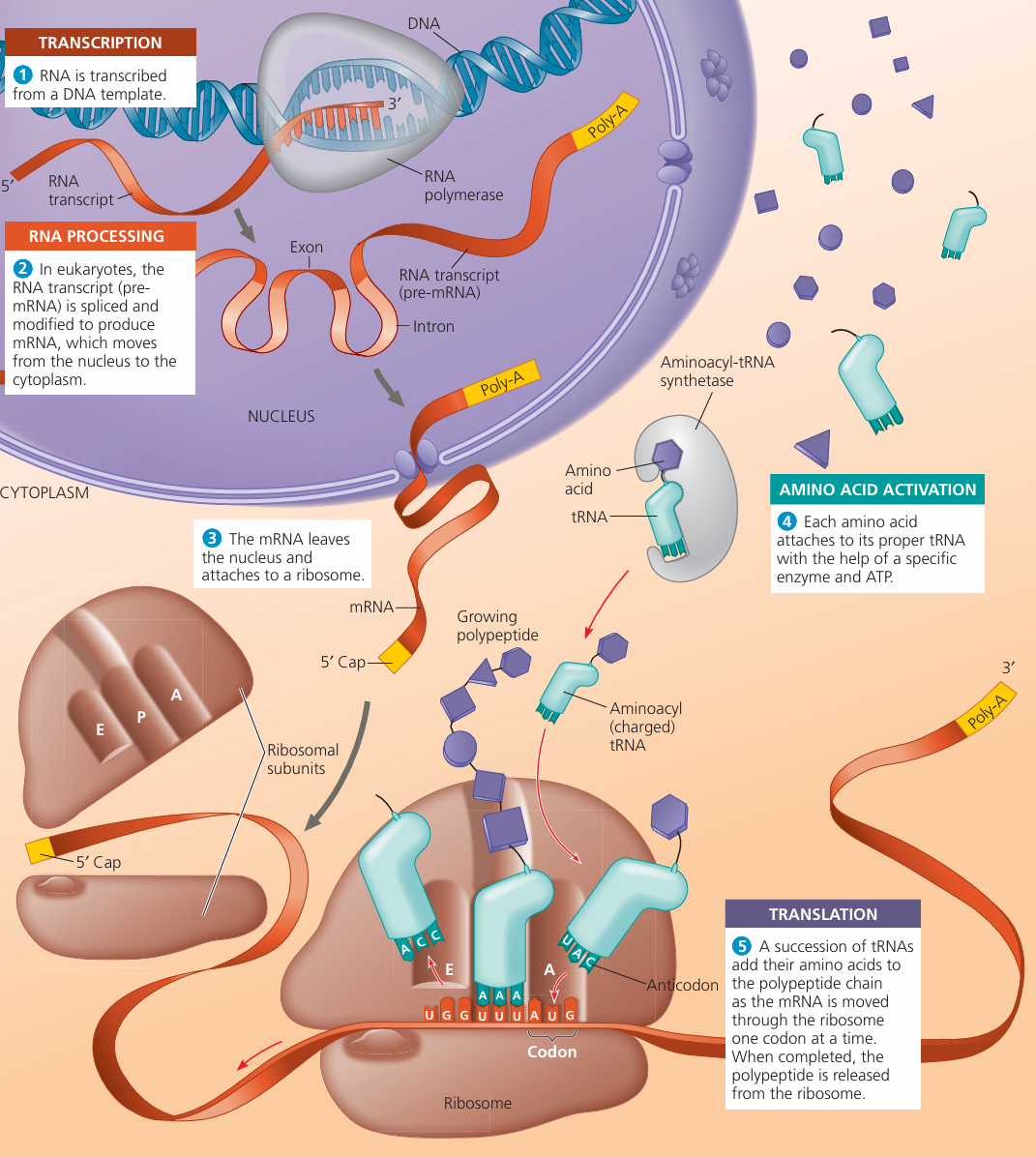
📌 Key Statement
- A polypeptide is coded for by a gene.
- A gene is a specific sequence of nucleotides that forms part of a DNA molecule.
- This nucleotide sequence contains the instructions for assembling a particular polypeptide (protein) by specifying the order of amino acids.
🔍 Explanation
- DNA stores genetic information in the form of triplet codes (three-nucleotide sequences called codons in mRNA after transcription).
- Each gene corresponds to a unique sequence of codons that determine the sequence of amino acids in a polypeptide.
- Central Dogma of Molecular Biology: DNA → mRNA → Polypeptide (via transcription and translation).
🧠 Example
- The insulin gene in humans contains a sequence of nucleotides that, when transcribed and translated, produces the insulin polypeptide (hormone regulating blood glucose).
Summary:
– A gene is a section of DNA made up of a specific nucleotide sequence.
– Each gene carries the instructions to make one polypeptide.
– Polypeptides are chains of amino acids whose sequence is determined by the order of nucleotides in the gene.
– A gene is a section of DNA made up of a specific nucleotide sequence.
– Each gene carries the instructions to make one polypeptide.
– Polypeptides are chains of amino acids whose sequence is determined by the order of nucleotides in the gene.
Protein Synthesis – Transcription & Translation
🌱 Overview
- Protein synthesis occurs in two main stages:
- Transcription – DNA → mRNA (nucleus)
- Translation – mRNA → polypeptide (cytoplasm, at ribosomes)
1️⃣ Transcription (in the Nucleus)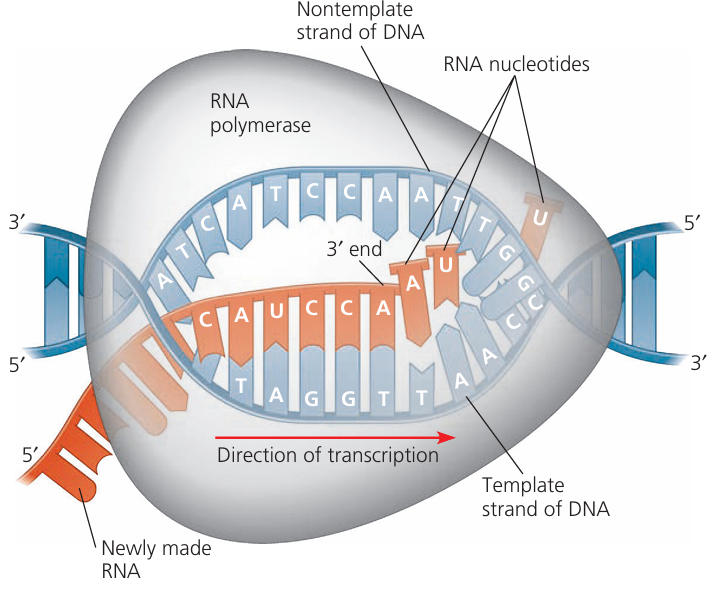
- Purpose: To produce a complementary mRNA copy of the gene.
- Steps:
- Initiation:
RNA polymerase binds to the promoter region of the gene.
DNA double helix unwinds, exposing the template strand. - Elongation:
RNA polymerase moves along the template DNA strand (3′ → 5′).
Matches RNA nucleotides to complementary DNA bases (A–U, T–A, G–C, C–G).
Forms messenger RNA (mRNA) with codons representing amino acids. - Termination:
RNA polymerase reaches a terminator sequence; mRNA detaches.
DNA helix reforms. - Post-transcriptional processing (in eukaryotes):
Introns removed, exons joined (splicing).
5′ cap and poly-A tail added for stability.
- Initiation:
2️⃣ Translation (at Ribosomes in Cytoplasm)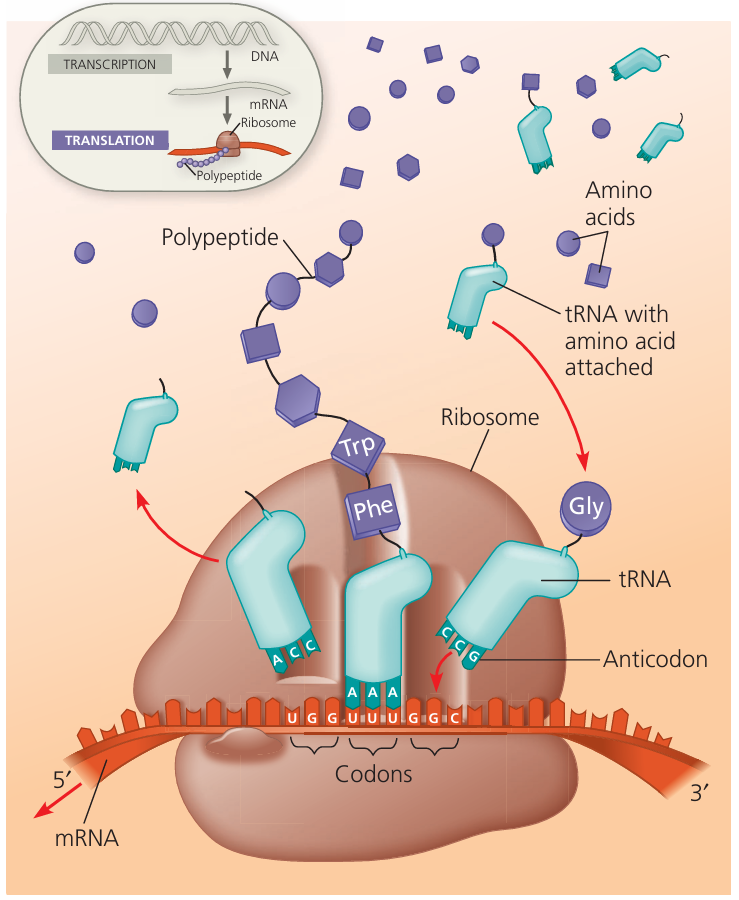
- Purpose: To use mRNA codons to assemble a polypeptide.
- Key Players:
- mRNA: carries genetic code from DNA to ribosome.
- tRNA (transfer RNA): delivers specific amino acids to ribosome; has an anticodon complementary to mRNA codon.
- Ribosome: site of protein synthesis; moves along mRNA, catalyses peptide bond formation.
- Steps:
- Initiation:
Ribosome binds to mRNA near the start codon (AUG).
First tRNA (anticodon UAC) carrying methionine binds. - Elongation:
Ribosome moves along mRNA, codon by codon.
Each codon is matched by a tRNA anticodon.
Amino acids linked by peptide bonds (via peptidyl transferase activity). - Termination:
Ribosome reaches a stop codon (UAA, UAG, UGA).
No tRNA matches → release factors detach ribosome, polypeptide released.
- Initiation:
📊 Roles of Key Components
| Component | Role |
|---|---|
| RNA polymerase | Catalyses mRNA synthesis from DNA template during transcription |
| mRNA | Carries genetic code (codons) from DNA to ribosome |
| Codons | Three-base sequences in mRNA that specify amino acids |
| tRNA | Delivers specific amino acids to ribosome |
| Anticodons | Three-base sequences on tRNA that pair with mRNA codons |
| Ribosomes | Assemble amino acids into polypeptides and catalyse peptide bond formation |
Summary:
– Transcription (nucleus) produces mRNA from DNA using RNA polymerase.
– mRNA codons are read by ribosomes during translation (cytoplasm).
– tRNA anticodons ensure correct amino acid sequence.
– Ribosomes link amino acids via peptide bonds to form a polypeptide.
– Transcription (nucleus) produces mRNA from DNA using RNA polymerase.
– mRNA codons are read by ribosomes during translation (cytoplasm).
– tRNA anticodons ensure correct amino acid sequence.
– Ribosomes link amino acids via peptide bonds to form a polypeptide.
RNA Processing in Eukaryotes
🌱 Key Point

- In eukaryotic cells, the RNA formed immediately after transcription is called the primary transcript (or pre-mRNA).
- This primary transcript cannot be used directly for protein synthesis—it must be processed into mature mRNA.
🔬 Steps in RNA Processing
- Splicing – removal of introns
- Introns = non-coding sequences of DNA/RNA that do not code for amino acids.
 Removed by a complex called the spliceosome.
Removed by a complex called the spliceosome.
- Joining of Exons
- Exons = coding sequences that contain instructions for making a protein.
- After introns are removed, exons are joined in the correct order to produce a continuous coding sequence.
- Additional Modifications (for stability and translation)
- 5′ cap: Modified guanine nucleotide added to the 5′ end—protects mRNA from degradation and helps ribosome binding.
- Poly-A tail: Chain of adenine nucleotides added to the 3′ end—increases stability.
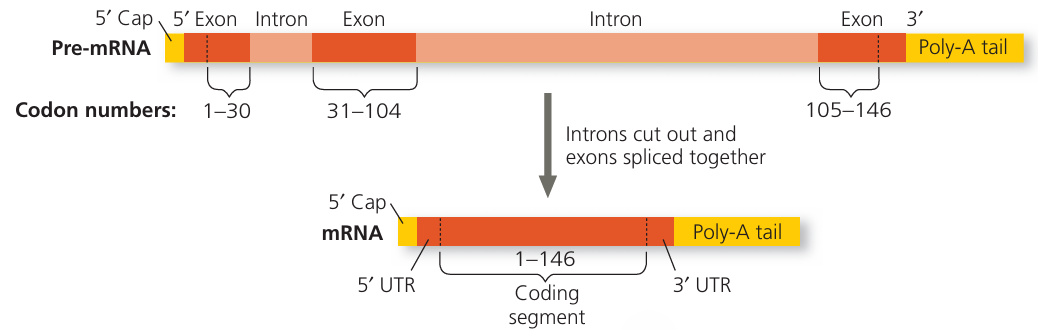
📌 Example
- Gene sequence: Exon 1 – Intron – Exon 2 – Intron – Exon 3
- After RNA processing → Exon 1 – Exon 2 – Exon 3 (mature mRNA)
| Term | Meaning |
|---|---|
| Primary transcript (pre-mRNA) | RNA directly after transcription, contains both exons and introns |
| Introns | Non-coding sequences removed during RNA processing |
| Exons | Coding sequences joined to form mature mRNA |
| Mature mRNA | Processed RNA with only exons, ready for translation |
Summary:
– Transcription produces pre-mRNA with both exons and introns.
– Introns are removed, exons are joined (splicing).
– Additional modifications (5′ cap and poly-A tail) produce stable, mature mRNA for translation.
– Transcription produces pre-mRNA with both exons and introns.
– Introns are removed, exons are joined (splicing).
– Additional modifications (5′ cap and poly-A tail) produce stable, mature mRNA for translation.