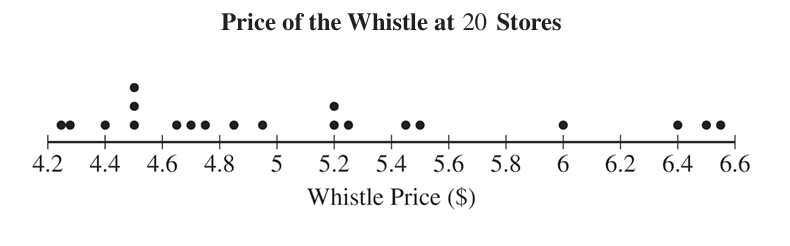
A company sells a certain type of whistle. The price of the whistle varies from store to store. Julio, a statistician at the company, wants to estimate the mean price, in dollars (\(\$\)), of this type of whistle at all stores that sell the whistle.
(a) (i) Identify the appropriate inference procedure for Julio to use.
(ii) Describe the parameter for the inference procedure you identified in part (a-i) in context.
Julio called the managers of \(20\) randomly selected stores that sell the whistle and recorded the price of the whistle at each store. Following is a dotplot of Julio’s data.
The summary statistics for Julio’s data are shown in the following table.
| Sample Size | Mean | Std Dev | Min | \(Q_1\) | Median | \(Q_3\) | Max |
|---|
| \(20\) | \(5.12\) | \(0.743\) | \(4.25\) | \(4.51\) | \(4.885\) | \(5.475\) | \(6.58\) |
(b) Julio wants to examine some characteristics of the distribution of the sample of whistle prices.
(i) Describe the shape of the distribution of the sample of whistle prices. Justify your response using appropriate values from the summary statistics table.
(ii) Using the \(1.5 \times IQR\) rule, determine whether there are any outliers in the sample of whistle prices. Justify your response.
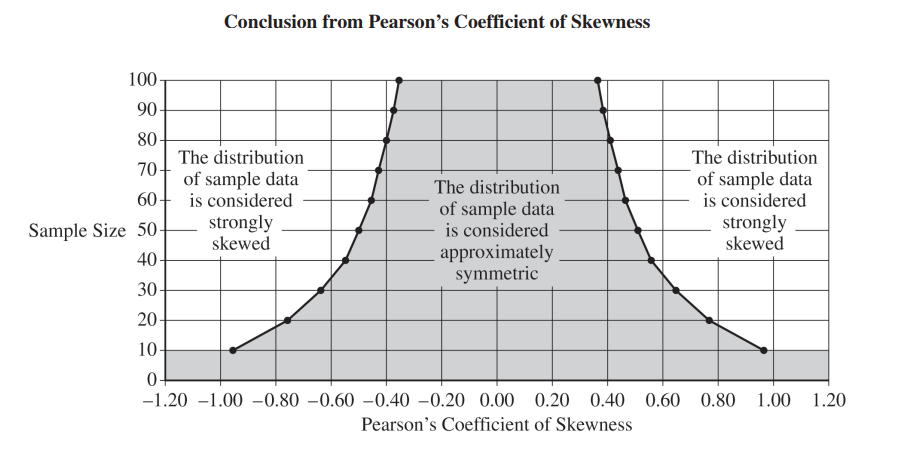
It can often be difficult to determine whether the distribution of sample data is skewed by looking at a graph of the data and the summary statistics, particularly when the sample size is small. Thus, statisticians sometimes measure how skewed a data set is. One such measure is Pearson’s coefficient of skewness, which is calculated using the following formula.
\[ \text{Pearson’s Coefficient of Skewness} \;=\; \frac{3\!\left(\bar{x}-m\right)}{s} \]
In the formula, \(\bar{x}\) is the sample mean, \(m\) is the sample median, and \(s\) is the sample standard deviation.
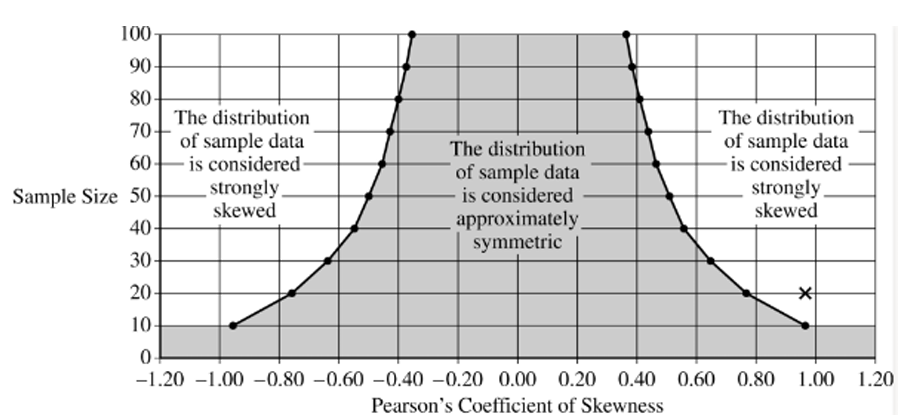
(c) (i) Calculate Pearson’s coefficient of skewness for Julio’s sample of \(20\) whistle prices. Show your work.
(ii) Indicate the value of the Pearson’s coefficient of skewness you calculated in part (c-i) for the appropriate sample size by marking it with an “X” on the preceding graph.
(d) Consider your work in part (c).
(i) What should you conclude about the shape of the distribution of the sample of whistle prices? Justify your response.
Julio’s inference procedure in part \((a\text{-}i)\) needs one of the following requirements to be satisfied to verify the normality condition.
- The sample size is greater than or equal to \(30\).
- If the sample size is less than \(30\), the distribution of the sample data is not strongly skewed and does not have outliers.
(ii) Using your response to (d-i) and the preceding requirements, is the normality condition satisfied for Julio’s data? Explain your response.
Most-appropriate topic codes (CED):
• TOPIC 7.2: Constructing a Confidence Interval for a Population Mean
• TOPIC 1.6: Describing the Distribution of a Quantitative Variable
• TOPIC 1.7: Summary Statistics for a Quantitative Variable