▶️ Answer/Explanation
The correct option is c.
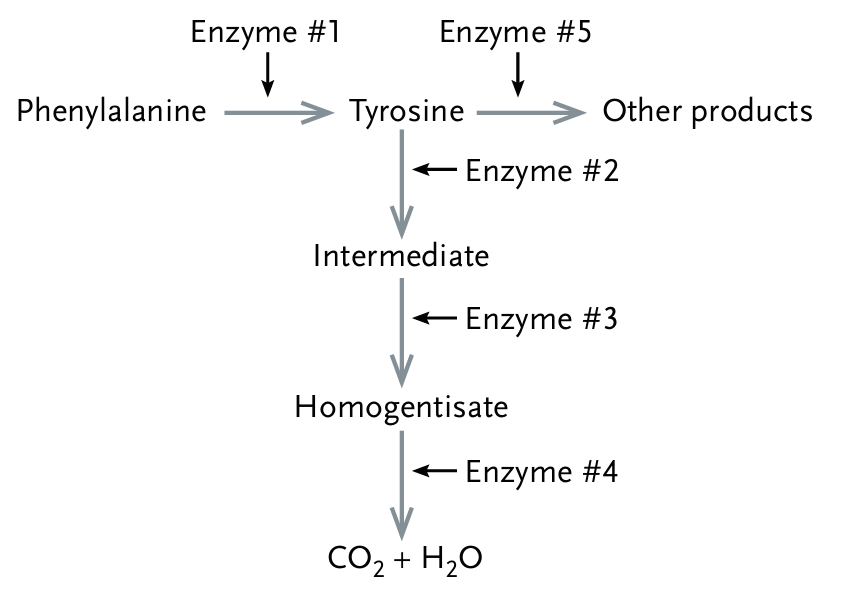
Enzyme $\#3$ catalyzes the conversion of the Intermediate into Homogentisate.
If a mutation destroys enzyme $\#3$, the pathway is blocked at that specific step.
Consequently, Homogentisate cannot be produced, leading to a deficiency of that product.
Option a is incorrect because enzyme $\#1$ produces tyrosine; its loss would decrease tyrosine.
Option b is incorrect because tyrosine is a precursor to enzyme $\#2$, not a product of it.
Option d is incorrect because a downstream mutation (enzyme $\#4$) cannot mask the loss of an upstream product (from enzyme $\#1$).
▶️ Answer/Explanation
The correct answer is C. inversion.
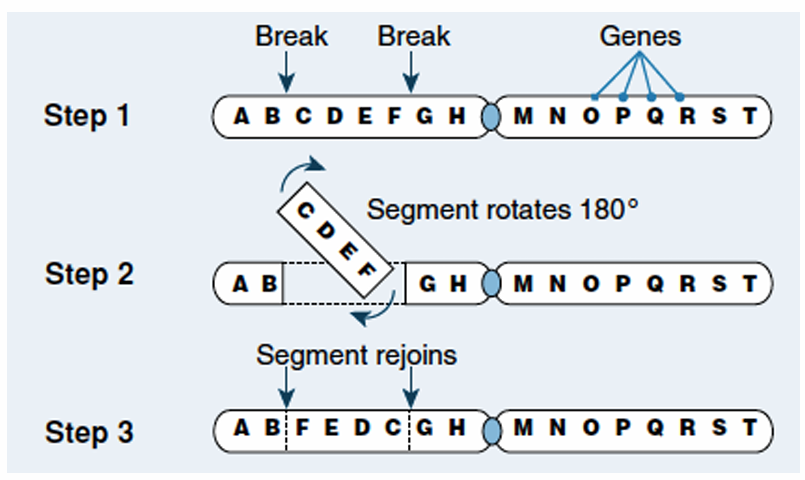
In Step $1$, two breaks occur within a single chromosome arm.
The segment containing genes $C$, $D$, $E$, and $F$ is detached.
In Step $2$, this specific segment rotates $180^{\circ}$.
In Step $3$, the segment rejoins the chromosome in reverse order.
The resulting gene sequence changes from $A-B-C-D-E-F-G-H$ to $A-B-F-E-D-C-G-H$.
Because the segment is flipped rather than lost or moved elsewhere, it is defined as an inversion.
▶️ Answer/Explanation
The correct option is D.
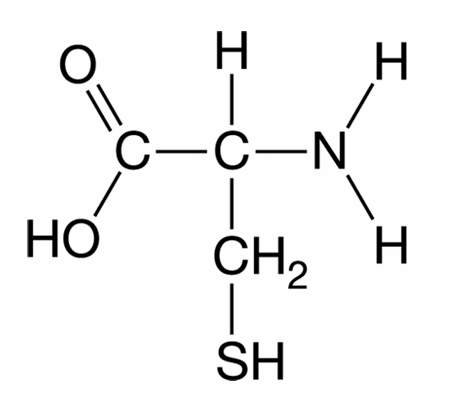
Cysteine contains a sulfhydryl ($-SH$) group in its $R$-group side chain.
Two cysteine side chains can oxidize to form a covalent disulfide bridge ($-S-S-$).
If this bond forms within a single polypeptide chain, it stabilizes the tertiary structure.
If the bond forms between different polypeptide subunits, it stabilizes the quaternary structure.
Secondary structure is primarily stabilized by hydrogen bonds between the backbone, not $R$-groups.
Therefore, the classification depends entirely on whether the bond is intra-chain or inter-chain.