The Normal Distribution Model
The normal distribution is a symmetric, bell-shaped distribution that is fully described by two parameters: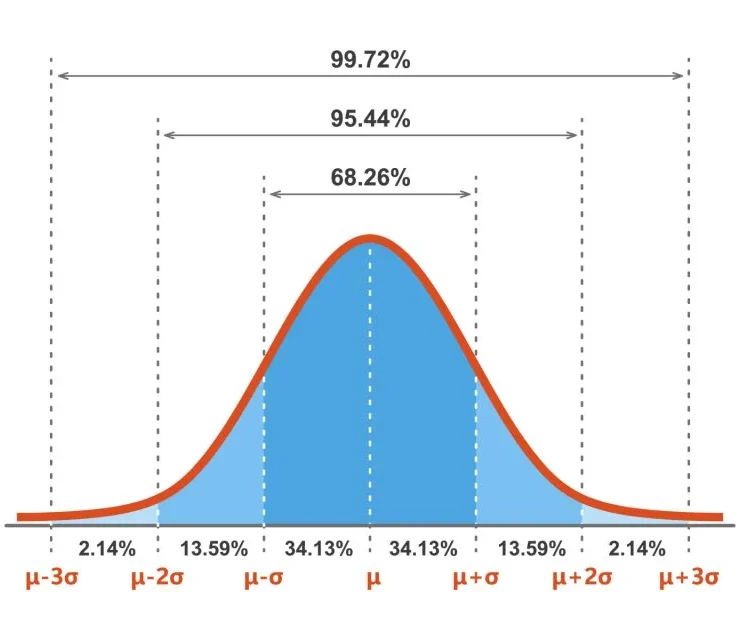
- \( \mu \) = mean (center of the distribution).
- \( \sigma \) = standard deviation (controls the spread).
It follows the empirical rule (68–95–99.7 rule):
- About 68% of data fall within 1 standard deviation of the mean (\( \mu \pm \sigma \)).
- About 95% within 2 standard deviations (\( \mu \pm 2\sigma \)).
- About 99.7% within 3 standard deviations (\( \mu \pm 3\sigma \)).
Notation: \( X \sim N(\mu, \sigma) \).
Comparing a Data Distribution to the Normal Model
Step 1: Shape
- Check if the distribution is roughly symmetric and bell-shaped.
- Look for skewness, outliers, or multiple peaks (these indicate non-normality).
Step 2: Center and Spread
- Compare the sample mean and standard deviation with what would be expected in a normal distribution.
- Apply the 68–95–99.7 rule to see if data frequencies fit roughly within the expected ranges.
Step 3: Quantitative Tests or Plots
- Normal probability plot (Q–Q plot): If data are normal, points lie close to a straight diagonal line.
- Histogram overlay: Compare the histogram of data to a normal curve with the same mean and standard deviation.
- Boxplot: Check for symmetry and outliers (normal data → symmetric box, no extreme outliers).
Key Point
In AP Statistics, you must clearly state whether the data are approximately normal or not, and justify based on shape, spread, and adherence to the empirical rule.
Example
A class of 50 students reports their heights (in cm). The summary statistics are:
- Mean = 168 cm
- Standard deviation = 6 cm
- Minimum = 150 cm
- Maximum = 185 cm
- The histogram is roughly symmetric, unimodal, and bell-shaped with no extreme outliers.
Determine whether the height distribution is approximately normal.
▶️ Answer / Explanation
Step 1: Shape The histogram shows a roughly symmetric and unimodal bell shape. No strong skewness or unusual peaks are observed.
Step 2: Spread (Empirical Rule Check)
- Mean = 168, SD = 6.
- \( \mu \pm \sigma \): 162 to 174 → about 34 students (68%) fall here.
- \( \mu \pm 2\sigma \): 156 to 180 → about 47 students (94%) fall here.
- \( \mu \pm 3\sigma \): 150 to 186 → all 50 students (100%) fall here.
- This matches the 68–95–99.7 rule closely.
Step 3: Outliers Minimum = 150, Maximum = 185. Both values are within 3 SDs of the mean, so there are no extreme outliers.
Conclusion: The student heights are approximately normal because the distribution is symmetric, unimodal, follows the empirical rule, and has no outliers.