▶️ Answer/Explanation
(a)
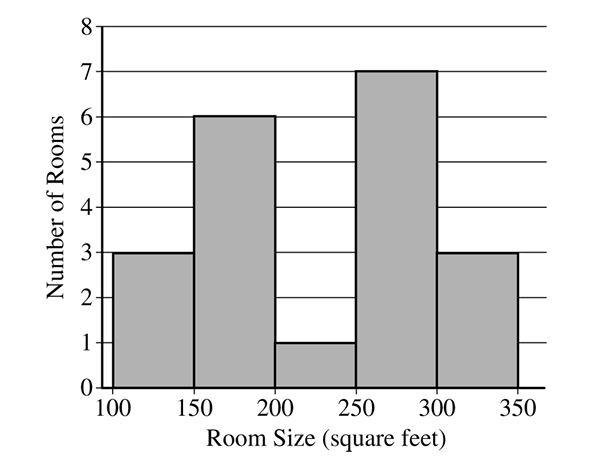
The distribution of room sizes is bimodal, with two distinct clusters of data. One cluster is between \(150\) and \(200\) square feet, and the other is between \(250\) and \(300\) square feet. The distribution is roughly symmetric with a center between \(200\) and \(250\) square feet. The range of the data is approximately \(350 – 100 = 250\) square feet.
(b)
First, determine potential outliers using the \(1.5 \times IQR\) rule.
– \(IQR = Q_3 – Q_1 = 292 – 174 = 118\).
– Lower Fence: \(Q_1 – 1.5(IQR) = 174 – 1.5(118) = 174 – 177 = -3\).
– Upper Fence: \(Q_3 + 1.5(IQR) = 292 + 1.5(118) = 292 + 177 = 469\).
Since the minimum value (\(134\)) is greater than the lower fence and the maximum value (\(315\)) is less than the upper fence, there are no potential outliers.
The boxplot is sketched below:
(c)
The most apparent characteristic visible in the histogram but not the boxplot is the **bimodal shape** of the distribution. The histogram clearly shows two distinct peaks, while the boxplot only shows a symmetric distribution with a wide interquartile range, hiding the two separate clusters of data.
▶️ Answer/Explanation
(a)
Because the sample was taken from a Web site where people voluntarily list available apartments, the results can be generalized to the population of one-bedroom apartments listed on that particular Web site for that city.
(b)
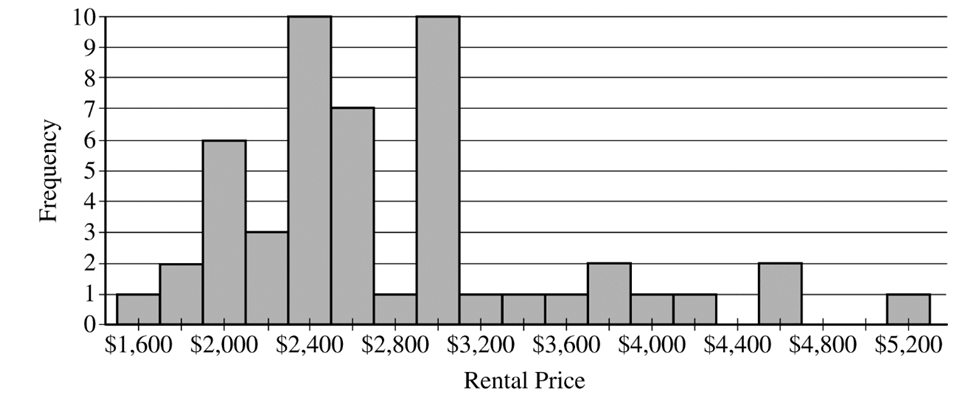
The histogram shows that the distribution of rental prices is skewed to the right. In a right-skewed distribution, the mean is pulled toward the long tail of higher prices and will be greater than the median. This would lead to an overestimation of the typical rental price.
(c)
To create the theoretical sampling distribution, one would have to take every possible unique random sample of size \(50\) from the entire population of apartment listings on the Web site. Then, the median for each of these samples would be calculated. The distribution of all these sample medians would form the theoretical sampling distribution.
(d)
(i) The \(5^{th}\) percentile is at position \(15,000 \times 0.05 = 750\). Summing the frequencies from the start of the table, we find the \(750^{th}\) value falls within the group of medians with a value of \(\$2,500\).
(ii) The \(95^{th}\) percentile is at position \(15,000 \times 0.95 = 14,250\). Summing the frequencies, we find the \(14,250^{th}\) value falls within the group of medians with a value of \(\$2,950\).
(e)
We need to find the percentage of the \(15,000\) medians that are between \(\$2,500\) and \(\$2,950\), inclusive. The number of medians less than \(\$2,500\) is \(1+13+18+56+4+56+55+3+66+136 = 408\). The number of medians greater than \(\$2,950\) is \(93+6+65+12+1+6+2+3 = 188\).
The number of medians at or between these values is \(15,000 – 408 – 188 = 14,404\).
Percentage = \(\frac{14,404}{15,000} \times 100\% \approx 96.03\%\).
(f)
An approximate \(96\%\) confidence interval for the median rental price is \((\$2,500, \$2,950)\).
Interpretation: We are approximately \(96\%\) confident that the true median rental price of all one-bedroom apartments listed on this Web site for this city is between \(\$2,500\) and \(\$2,950\).