A1.2.2 – Components of a Nucleotide
1. What is a Nucleotide?
- A nucleotide is the basic building block (monomer) of nucleic acids like DNA and RNA
- Nucleotides join together to form long chains of DNA or RNA
Each nucleotide consists of three distinct parts that work together to form the repeating unit of genetic molecules.
Nucleotides = Phosphate + Sugar + Nitrogenous Base → form the core of DNA/RNA structure.
2. The Three Components of a Nucleotide
| Component | Description |
|---|---|
| Phosphate group | A negatively charged group (contains phosphorus) |
| Pentose sugar | 5-carbon sugar: deoxyribose (DNA) or ribose (RNA) |
| Nitrogenous base | Nitrogen-containing base (A, T, G, C, U) |
3. Visual Representation (for Diagrams)
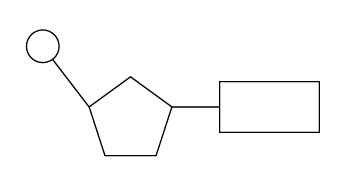
- Circle = Phosphate
- Pentagon = Sugar (pentose)
- Rectangle = Nitrogenous base
- Connected in the order: Phosphate → Sugar → Base
4. Sugar Structure – Carbon Numbering
- The sugar ring contains 5 carbon atoms, labeled 1′ to 5′ (prime)
- Numbering starts at the oxygen atom in the ring and moves clockwise
- Phosphate group binds to the 5′ carbon, base binds to the 1′ carbon
A1.2.3 – Sugar – Phosphate Bonding and the Backbone of DNA & RNA
1. What is the Sugar-Phosphate Backbone?
- It’s the strong structural framework of DNA and RNA strands.
- Made of alternating phosphate and sugar units (from each nucleotide).
- Called the “backbone” because it holds the strand together and maintains sequence order.
2. How is the Backbone Formed?
The sugar–phosphate backbone gives DNA and RNA their structural stability and polarity (5′ to 3′).
Nucleotides are joined by covalent bonds between:
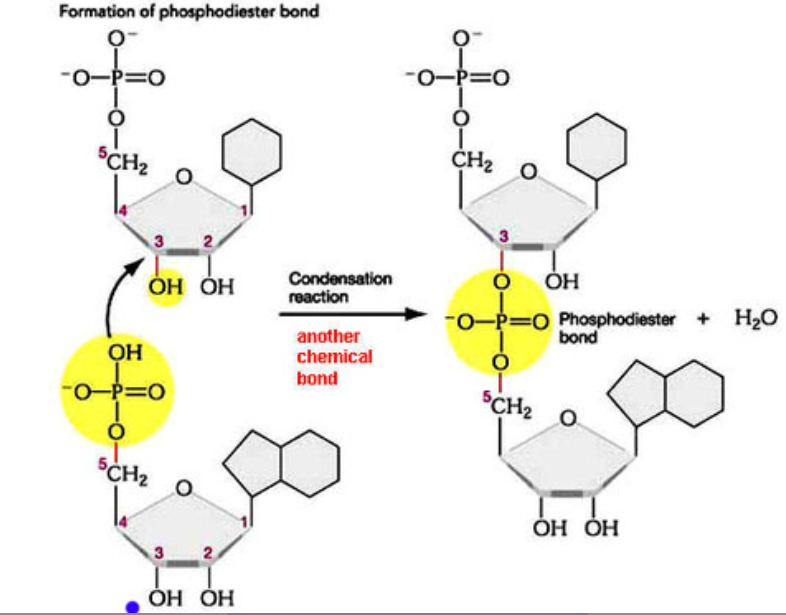
- The 5′ phosphate group of one nucleotide
- The 3′ carbon of the sugar on the next nucleotide
This process is a condensation reaction, which releases a molecule of water.
3. Directionality of the Strand
Nucleic acid strands run from 5′ to 3′ direction.
The backbone follows a repeated pattern:
This continuous covalent chain creates a strong and stable strand.
🔹 Key Terms
| Term | Meaning |
|---|---|
| Backbone | The sugar–phosphate chain that forms the structural framework of DNA/RNA |
| 5′ to 3′ linkage | Direction of bonding between phosphate and sugar in nucleotide chains |
| Condensation reaction | A reaction that forms a bond and releases water as a byproduct |
A1.2.4 – Nitrogenous Bases: The Code of Life
1️⃣ What Are Nitrogenous Bases?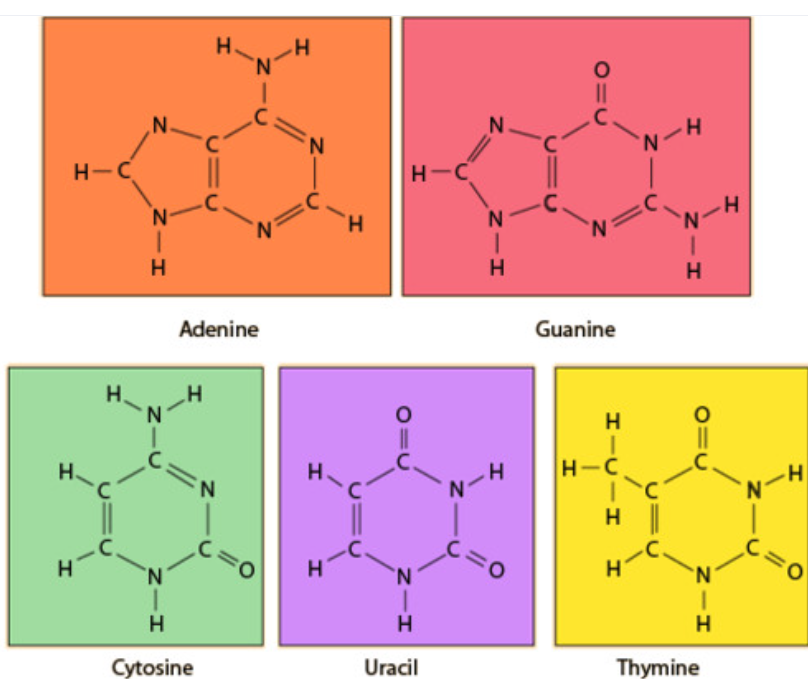
Nucleotides contain a nitrogen-containing base. These bases form the genetic code.
| Base | Found In |
|---|---|
| Adenine (A) | DNA & RNA |
| Guanine (G) | DNA & RNA |
| Cytosine (C) | DNA & RNA |
| Thymine (T) | DNA only |
| Uracil (U) | RNA only |
2️⃣ The Genetic Code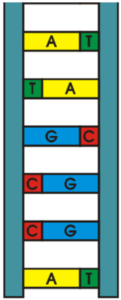
The sequence of these bases in a DNA or RNA molecule forms a genetic code.
Each triplet of bases (called a codon) codes for one amino acid.
This sequence ultimately determines the structure of proteins.
🧪Gene: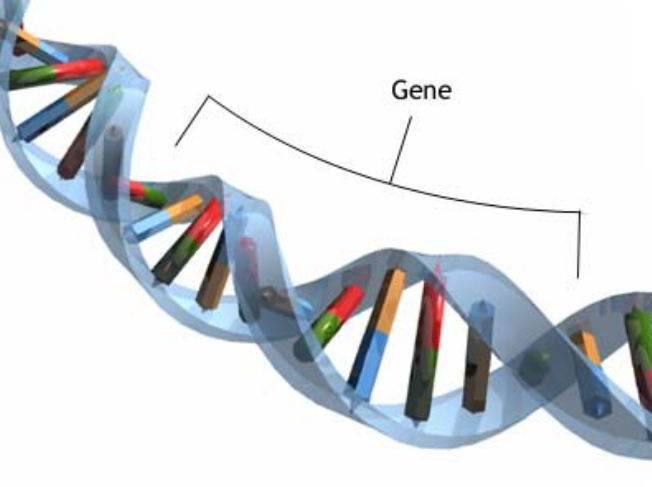
A gene is a specific sequence of DNA bases that codes for the creation of a particular protein.
Example:
A DNA gene with the base sequence ATG–GCC–TGA will be translated into a chain of amino acids that form a specific protein.
A1.2.5 – RNA as a Polymer Formed by Condensation of Nucleotide Monomers
1️⃣ What is RNA Made Of?
RNA is a single-stranded polymer made up of nucleotide monomers.
Each RNA nucleotide contains:
- A phosphate group (circle)
- A ribose sugar (pentagon/hexagon)
- A nitrogenous base (rectangle – A, U, C, G)
RNA = Ribose sugar + Phosphate group + Nitrogenous base (A, U, C, G)
2️⃣ Formation of RNA Polymer
RNA nucleotides join via a condensation reaction.
The 5′ phosphate of one nucleotide bonds with the 3′ carbon of the ribose on the next.
3️⃣ Structure of an RNA Strand
An RNA strand has a sugar–phosphate backbone with nitrogenous bases projecting outwards.
It has a defined 5′ → 3′ direction, which is essential for processes like transcription.
Represent an RNA nucleotide as:
🟡 Circle = Phosphate 🔷 Pentagon/Hexagon = Ribose 📦 Rectangle = Nitrogenous Base
Connect 5′ phosphate to 3′ carbon of the next sugar to show the bonding direction.
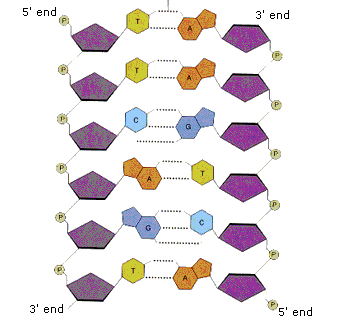
A1.2.6 – DNA as a Double Helix Made of Two Antiparallel Strands Linked by Hydrogen Bonds Between Complementary Base Pairs
1. DNA: A Double-Stranded Molecule
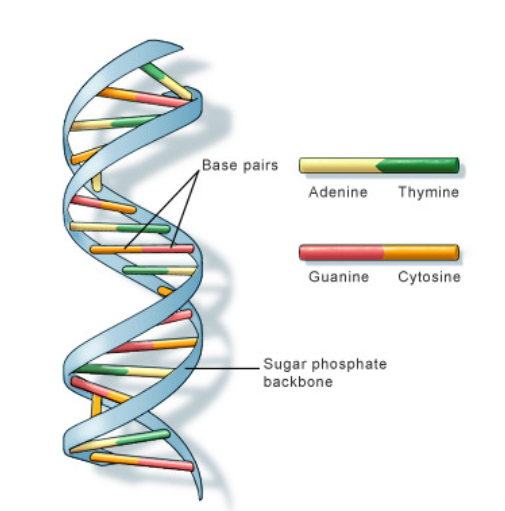
- DNA (Deoxyribonucleic acid) consists of two long nucleotide chains that form a twisted, ladder-like double helix.
- Each strand has a sugar–phosphate backbone with inward-facing nitrogenous bases.
2. Antiparallel Arrangement
– One DNA strand runs 5′ to 3′, the other 3′ to 5′
– This antiparallel nature is essential for:
- Accurate base pairing
- DNA replication by enzymes like DNA polymerase
- Correct reading direction for enzyme function
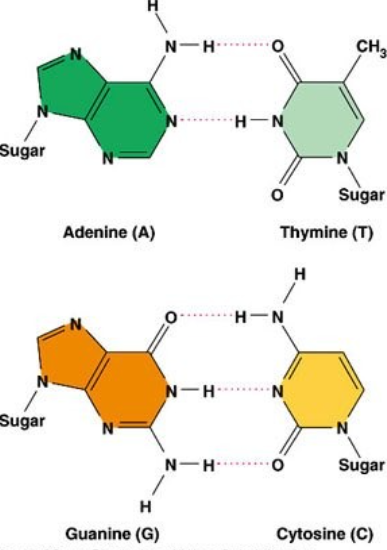
3. Base Pairing and Hydrogen Bonds
The nitrogenous bases form specific pairs by hydrogen bonding:
- Adenine (A) pairs with Thymine (T) → 2 hydrogen bonds
- Guanine (G) pairs with Cytosine (C) → 3 hydrogen bonds
This is called complementary base pairing and it:
- Ensures genetic consistency during DNA replication
- Allows easy separation for replication or transcription
4. Importance of Hydrogen Bonding
5. Summary of Key Features
| Feature | Description |
|---|---|
| Double helix | Two nucleotide strands twisted around each other |
| Antiparallel strands | One strand runs 5′→3′, the other 3′→5′ |
| Complementary base pairing | A–T and G–C pairing with hydrogen bonds |
| Hydrogen bonds | Hold strands together, allow easy separation |
| Sugar–phosphate backbone | Gives stability and direction to the strands |
| Biological significance | Ensures accurate copying and storage of DNA |
🔍 Why It Matters
Without complementary base pairing, DNA replication would be error-prone.
Without hydrogen bonds, the double helix would be too unstable to preserve genetic code.
A1.2.7 – Differences Between DNA and RNA
1. Common Features of DNA & RNA
- Both are nucleic acids
- Both are polymers of nucleotides
- Both have a sugar–phosphate backbone
- Both store and carry genetic information
- Both are formed via condensation reactions
DNA and RNA differ in structure, function, and stability, but share the same basic building blocks.
2. Key Differences Between DNA and RNA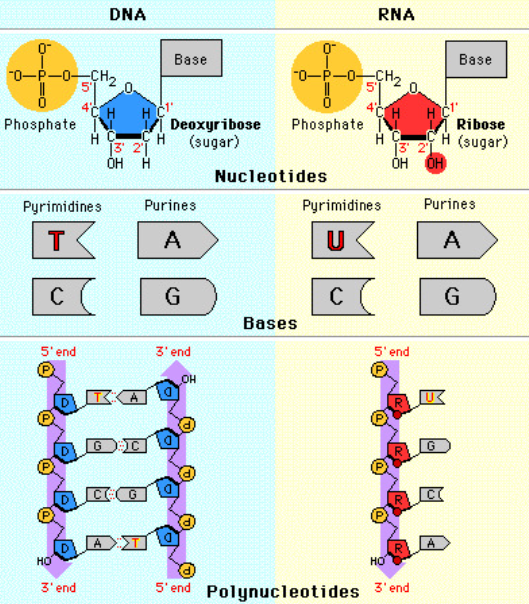
| Feature | DNA | RNA |
|---|---|---|
| Full name | Deoxyribonucleic acid | Ribonucleic acid |
| Strands | Double-stranded (helix) | Single-stranded |
| Sugar | Deoxyribose | Ribose |
| Bases | A, T, G, C | A, U, G, C |
| Base pairing | A–T, C–G | A–U, C–G |
| Stability | More stable | Less stable |
| Functions | Stores genetic code | Protein synthesis roles |
3. Structural Difference in Sugars
➡️ Students should sketch both sugars showing the extra –OH group on ribose.
4. Location in Cells
| Feature | DNA | RNA |
|---|---|---|
| Eukaryotic cells | Nucleus, mitochondria, chloroplasts | Nucleus, cytoplasm, ribosomes, rough ER |
| Prokaryotic cells | Cytoplasm (nucleoid region) | Cytoplasm (free or at ribosomes) |
5. Examples of Nucleic Acids
- DNA: Human genome, bacterial chromosomes, mitochondrial DNA
- RNA types:
- mRNA – Messenger RNA (carries genetic message)
- tRNA – Transfer RNA (helps assemble proteins)
- rRNA – Ribosomal RNA (forms ribosomes)
📘 Summary Table
| Criteria | DNA | RNA |
|---|---|---|
| Strand Type | Double | Single |
| Sugar | Deoxyribose | Ribose |
| Bases | A, T, G, C | A, U, G, C |
| Base Pairing | A–T, C–G | A–U, C–G |
| Location | Nucleus, mitochondria, chloroplasts | Nucleus, cytoplasm, ribosome |
| Function | Stores hereditary info | Protein synthesis |
A1.2.8 – Role of Complementary Base Pairing in Genetic Replication and Expression
1. What is Complementary Base Pairing?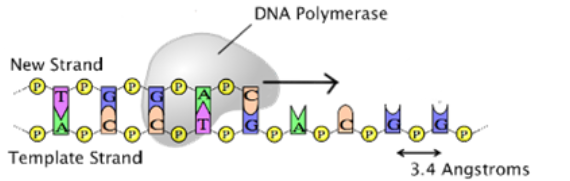
- Adenine (A) pairs with Thymine (T) in DNA
- Adenine (A) pairs with Uracil (U) in RNA
- Cytosine (C) pairs with Guanine (G)
- This occurs due to hydrogen bonding between bases
2. Role in DNA Replication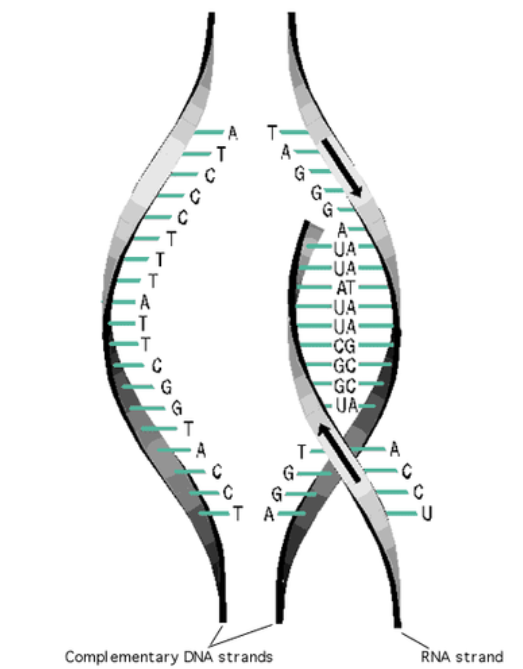
- Before cell division, DNA must replicate exactly
- The two strands unzip by breaking hydrogen bonds
- Each original strand acts as a template
- Free nucleotides pair up using base-pairing rules:
- A → T
- C → G
- Result: New strands are exact copies → ensures genetic stability
3. Role in Transcription (DNA → mRNA)
- One DNA strand serves as the template
- RNA bases pair with DNA to form mRNA:
- A (DNA) → U (RNA)
- T (DNA) → A (RNA)
- C (DNA) → G (RNA)
- G (DNA) → C (RNA)

- This produces a correct mRNA strand ready for protein synthesis
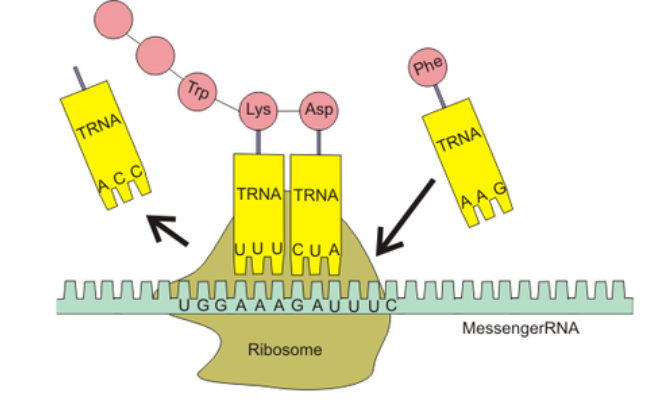
4. Role in Translation (mRNA → Protein)
- mRNA codons (triplets) are read by the ribosome
- Each codon pairs with a complementary anticodon on tRNA
- tRNA brings specific amino acids to the ribosome
- Base pairing ensures correct amino acid order → proper protein structure
5. Summary of Roles
| Process | How Complementary Base Pairing Helps |
|---|---|
| Replication | Ensures accurate DNA copying for cell division |
| Transcription | Builds the correct mRNA strand from DNA template |
| Translation | Matches tRNA anticodons to mRNA codons to assemble proteins |
Why It Matters:
Without complementary base pairing:
- DNA wouldn’t replicate accurately → mutations
- mRNA could carry incorrect instructions
- Proteins might form incorrectly → malfunctioning cells
It is the foundation for genetic fidelity, heredity, and gene expression.
A1.2.9 – Diversity of DNA Base Sequences and the Limitless Capacity of DNA for Storing Information
1. DNA is a Universal Information Storage Molecule
DNA uses four bases – A, T, C, and G – to encode genetic instructions.
- The order of bases forms the genetic code
- Each unique sequence → a unique protein-coding message
Four bases can be arranged in countless sequences, allowing DNA to store massive amounts of information.
2. Enormous Diversity Comes from Sequence and Length
- 4² = 16 possible 2-base sequences
- 4³ = 64 possible codons (triplets)
- 4ⁿ sequences possible for any length “n”
- 100-base DNA → more than 1.6 × 10⁶⁰ possible combinations
- Longer DNA molecules = virtually infinite storage potential
3. Economy of Storage
DNA stores huge amounts of data in a compact space:
- Each cell contains ~3 billion base pairs
- Total DNA in one cell spans ~2 meters
- All packed inside a tiny nucleus (≈ 6 µm)
DNA is incredibly efficient – it stores complex data in tiny spaces using just 4 bases!
4. DNA is Digital and Durable
- Functions like a biological hard drive
- Uses 4 chemical “letters”
- Linear structure → easy to copy and transmit
- Used in synthetic biology to store real-world data (texts, images, software!)
5. Biological Significance
- Allows for huge genetic variation among species
- Every individual has a unique DNA sequence
- Supports countless combinations of genes and proteins
- Despite sequence differences, all organisms share the same 4-base system
🔹 Summary Table
| Concept | Explanation |
|---|---|
| Base Sequence | Order of A, T, G, C determines genetic code |
| Sequence Length | Longer sequences = more possible combinations |
| Storage Potential | Essentially limitless with just 4 bases |
| Biological Outcome | Huge genetic diversity and individuality |
A1.2.10 – Conservation of the Genetic Code Across All Life Forms as Evidence of Universal Common Ancestry
1. What is the Genetic Code?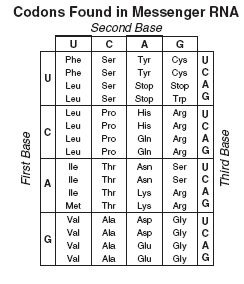
The genetic code is a system of rules for translating the base sequence in DNA or mRNA into a chain of amino acids (protein).
- It uses triplets of bases called codons
- Each codon codes for a specific amino acid or a stop signal
2. What Does ‘Universal Genetic Code’ Mean?
“Universal” means all living organisms use the same codon – amino acid mapping.
- Example: AUG codes for methionine in all life forms – bacteria, plants, humans
- Genetic code hasn’t changed through evolution
The same codons produce the same amino acids in all organisms – a shared biological “language”.
3. Evidence for Universal Common Ancestry
- All life shares the same genetic code logic
- Strong evidence that life evolved from a common ancestor
- Genetic code has been conserved for billions of years
4. Why It’s Important
The universality of the code allows scientists to:
- Compare genes between species
- Use bacteria to express human proteins (e.g., insulin)
- Support the theory of evolution via molecular evidence
The genetic code is like a global language – used identically in every known organism on Earth.
5. Summary Points
| Concept | Details |
|---|---|
| Genetic code | Triplet codons coding for amino acids |
| Universality | Same codons used across all life |
| Evolutionary link | Shared code = shared ancestry |
| Application | Biotech, gene transfer, evolutionary research |
Additional Higher Level
A1.2.11 – Directionality of RNA and DNA
1. What Does Directionality Mean in DNA/RNA?
Nucleic acids have two chemically distinct ends:
- 5′ (five-prime): Has a phosphate group on the 5th carbon of the sugar
- 3′ (three-prime): Has a hydroxyl group (-OH) on the 3rd carbon
The strand “grows” in the 5′ to 3′ direction – new nucleotides are always added at the 3′ end.
2. Antiparallel Nature of DNA
- DNA has two strands running in opposite directions
- One runs 5′ → 3′, the other 3′ → 5′
- This is critical for correct base pairing, replication, and enzyme action
3. Importance in Replication
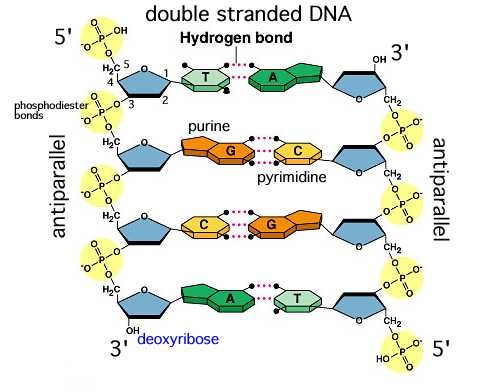
DNA polymerase can only add nucleotides to the 3′ end of a strand.
- So DNA is synthesized in the 5′ to 3′ direction
- Leads to:
- Leading strand: made continuously
- Lagging strand: made in fragments (Okazaki fragments)
4. Importance in Transcription
- RNA polymerase reads the DNA template strand from 3′ to 5′
- It builds mRNA in the 5′ to 3′ direction
- This ensures the mRNA is complementary and properly oriented
5. Importance in Translation
- Ribosomes read mRNA in the 5′ to 3′ direction
- Each codon (3 bases) corresponds to one amino acid
- This ensures correct reading frame and protein sequence
6. Quick Recap Table
| Process | Enzyme Reads | New Strand Made |
|---|---|---|
| Replication | DNA (3′ → 5′) | DNA (5′ → 3′) |
| Transcription | DNA template (3′ → 5′) | mRNA (5′ → 3′) |
| Translation | mRNA (5′ → 3′) | Polypeptide (amino acid chain) |
🔍 Why It Matters
Directionality ensures:
- Correct enzyme function and binding
- Accurate gene expression
- Proper protein synthesis
Even small directional mistakes can result in mutations or cellular malfunction.
A1.2.12 – Purine-to-Pyrimidine Bonding as a Component of DNA Helix Stability
1. What Are Purines and Pyrimidines?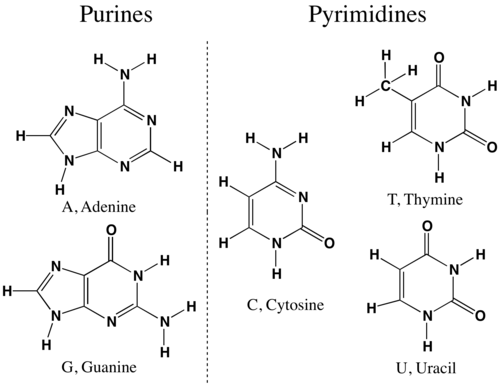
DNA bases are grouped based on their structure:
| Group | Structure | Bases |
|---|---|---|
| Purines | Double-ring | Adenine (A), Guanine (G) |
| Pyrimidines | Single-ring | Cytosine (C), Thymine (T), Uracil (U) |
2. Base Pairing: Purine–Pyrimidine Rule
Each base pair in DNA = one purine + one pyrimidine, keeping the helix width consistent:
| Pair | Type | # Hydrogen Bonds |
|---|---|---|
| A–T | Purine–Pyrimidine | 2 |
| C–G | Purine–Pyrimidine | 3 |
3. Why Is Purine–Pyrimidine Pairing Important?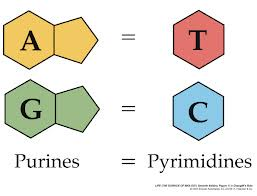
- Equal Width: Maintains uniform shape of DNA helix
- Hydrogen Bonds:
- A–T = 2 H-bonds → stable but easy to unzip
- C–G = 3 H-bonds → stronger, more heat resistant
- Ensures DNA stability and accurate replication
🔍 Quick Tips for Identifying Bases: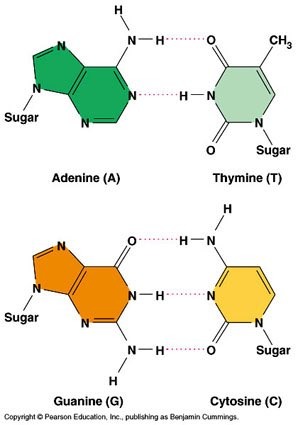
- 2 rings + 2 H-bonds → Adenine
- 2 rings + 3 H-bonds → Guanine
- 1 ring + 2 H-bonds → Thymine
- 1 ring + 3 H-bonds → Cytosine
4. RNA Note
In RNA, Uracil (U) replaces Thymine (T)
→ A–U forms 2 hydrogen bonds
DNA base pairing follows a purine-to-pyrimidine rule
This provides structural consistency and double helix stability
Hydrogen bonds and consistent spacing are vital for DNA’s biological function
A1.2.13 – Structure of a Nucleosome
1. What Is a Nucleosome?
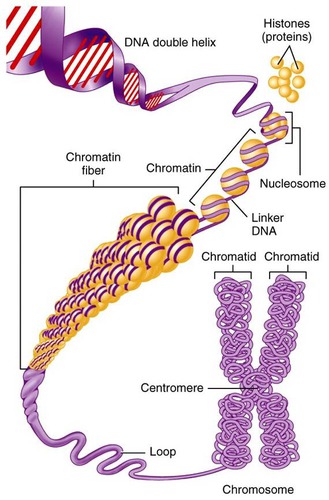
A nucleosome is the fundamental unit of DNA packaging in eukaryotic cells. It compacts long DNA strands while keeping them accessible for gene expression.
2. Components of a Nucleosome
| Component | Description |
|---|---|
| Histone octamer | Core of 8 histone proteins (2 each of H2A, H2B, H3, H4) |
| DNA | ~146 base pairs wrap around the histone core (2 loops) |
| Linker DNA | Stretch of DNA between nucleosomes |
| Histone H1 | Binds outside the core to stabilize and compact chromatin |
3. Step-by-Step DNA Packaging
- DNA Double Helix: The basic DNA strand
- Nucleosome Formation: DNA wraps around histone octamer
- “Beads-on-a-string”: Nucleosomes linked by linker DNA (interphase)
- Chromatin Fiber: Nucleosomes coil into 30 nm fibers
- Supercoiling: Chromatin twists into chromosomes (mitosis/meiosis)
4. Why Are Nucleosomes Important?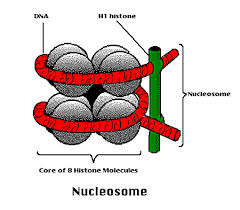
- Compaction: Fits large genomes into small nuclei
- Regulation: Controls access to genes for transcription
- Protection: Prevents DNA damage and maintains integrity
5. Visualization Tip
In molecular diagrams:
- 2 loops of DNA wrapped around the histone octamer
- H1 protein sits outside securing the structure
- Linker DNA connects adjacent nucleosomes
A nucleosome = DNA wrapped around a histone octamer, stabilized by H1 and linker DNA.
It is the first level of chromatin organization and is vital for packaging, gene regulation, and chromosome structure.
A1.2.14 – Evidence from the Hershey-Chase Experiment for DNA as the Genetic Material
🔍 Background: 
Before 1952, scientists were uncertain whether DNA or protein carried genetic information. Both were present in cells and seemed likely candidates.
Experimental question: Is DNA or protein the molecule responsible for heredity?
🦠 Organisms Used
- Bacteriophages – viruses that infect bacteria
- Escherichia coli (E. coli) – bacterial host cells
🧬 Key Idea of the Experiment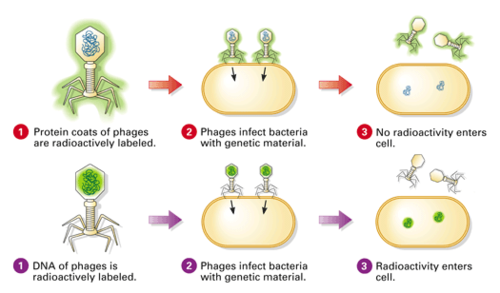
Hershey and Chase used radioactive isotopes to label:
- DNA with phosphorus-32 (32P) – because DNA contains phosphorus
- Protein with sulfur-35 (35S) – because proteins contain sulfur
⚗️ Step-by-Step Procedure
- Labeling: Phages were grown in media with either 32P or 35S
- DNA was labeled with 32P; protein with 35S
- Infection: Radioactive phages infected non-radioactive bacteria
- Blending: Agitation separated phage coats from bacterial cells
- Centrifugation: Heavier bacteria formed pellet; lighter phage coats remained in supernatant
- Results: 32P was found in pellet (inside bacteria), 35S in supernatant (outside)
DNA, not protein, entered the bacteria and directed the production of new phages.
This provided strong evidence that DNA is the genetic material.
⚙️ Role of Technology (Nature of Science)
The use of radioisotopes was essential. Availability after WWII allowed scientists to track molecules precisely.  This experiment is a prime example of how new technology can enable scientific breakthroughs.
This experiment is a prime example of how new technology can enable scientific breakthroughs.
🧪 Radioisotopes in Biology
- Radioactive isotopes like 32P and 35S act as tracers
- They emit detectable radiation, helping scientists follow molecular pathways
- Used today in DNA/RNA studies, metabolism research, and medical imaging
The Hershey–Chase experiment (1952) proved that DNA is the molecule of heredity
Used radioactive labels to distinguish DNA and protein
Only DNA entered bacterial cells and passed on instructions
Shifted scientific consensus toward DNA as the universal genetic material
A1.2.15 – Chargaff’s Data on Base Ratios Across Life Forms
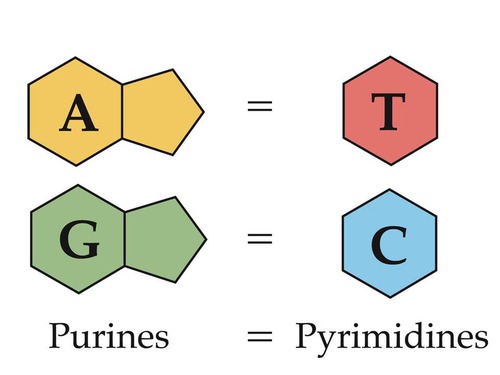
📊 What Did Chargaff Discover?
Erwin Chargaff analyzed DNA samples from various species and made a critical observation:
- Adenine (A) ≈ Thymine (T)
- Guanine (G) ≈ Cytosine (C)
- Thus, Purines (A, G) always equal Pyrimidines (T, C)
Although the overall percentage of each base varied between species, the ratio of A:T and G:C stayed close to 1:1.
📉 Falsification of the Tetranucleotide Hypothesis
The tetranucleotide hypothesis claimed that DNA was composed of repeating, equal amounts of the four bases — A = T = G = C.
Chargaff’s data showed this was false:
- Base composition differed among species
- But A:T and G:C ratios were always 1:1
Falsifiability Principle (Nature of Science)
- Science advances not by proving ideas, but by disproving incorrect ones.
- Chargaff’s evidence falsified the tetranucleotide model and cleared the path for more accurate models like the DNA double helix.
🧠 Induction vs. Falsification
- Induction: Generalizing from patterns (e.g., equal base ratios)
- Falsification: Actively disproving false models
- Chargaff’s work supported falsifiability as a stronger scientific method
🧬 How Did It Help Watson & Crick?
Though Chargaff didn’t suggest base pairing himself, Watson and Crick used his data to understand:
- A pairs with T, G pairs with C
- This led to their model of the double helix with a uniform width and stable hydrogen bonding
Chargaff discovered A:T ≈ 1 and G:C ≈ 1 in all species
Disproved the old tetranucleotide model (A = T = C = G)
Helped establish the base-pairing principle
Demonstrates how falsification drives scientific progress