D1.2.1 – Transcription: Synthesis of RNA Using a DNA Template
🔍 What is Transcription?
Transcription is the process of making RNA from a DNA template.
It is the first step in gene expression, leading to protein synthesis.
🛠️ Role of RNA Polymerase
- RNA polymerase binds to the promoter region on DNA.
- Unwinds the DNA strands.
- Adds RNA nucleotides complementary to the DNA template strand.
- Synthesizes RNA in the 5’ to 3’ direction.
- Only the template DNA strand is copied.
🧩 Result of Transcription
Produces a single-stranded messenger RNA (mRNA) molecule.
mRNA carries the genetic code from DNA to the ribosome for protein synthesis.
🔑 Key Points
- Transcription copies DNA into RNA.
- RNA polymerase controls the process.
- Only a gene (section of DNA) is transcribed.
Transcription is the process where RNA polymerase synthesizes RNA by copying one DNA strand, producing mRNA that carries genetic information for protein synthesis.
D1.2.4 – Transcription as a Process Required for Gene Expression
🔍 What is Gene Expression?
Gene expression is the process by which information from a gene is used to make a functional product, usually a protein.
Transcription is the first and crucial step in gene expression.
🔑 Control of Gene Expression
- Not all genes in a cell are active (expressed) at the same time.
- Cells regulate gene expression mainly by switching transcription on or off.
- When a gene is switched on, its DNA is transcribed into RNA.
- When a gene is switched off, transcription does not occur, so no RNA or protein is made.
⚙️ Why Control Transcription?
- Controls which proteins are produced according to the cell’s needs.
- Allows cells to respond to changes in the environment or developmental signals.
- Saves energy by only producing necessary proteins.
Transcription is the key first step in gene expression and is tightly regulated so that only certain genes are expressed at any time, allowing cells to control protein production.
D1.2.5 – Translation: Synthesis of Polypeptides from mRNA
🔍 What is Translation?
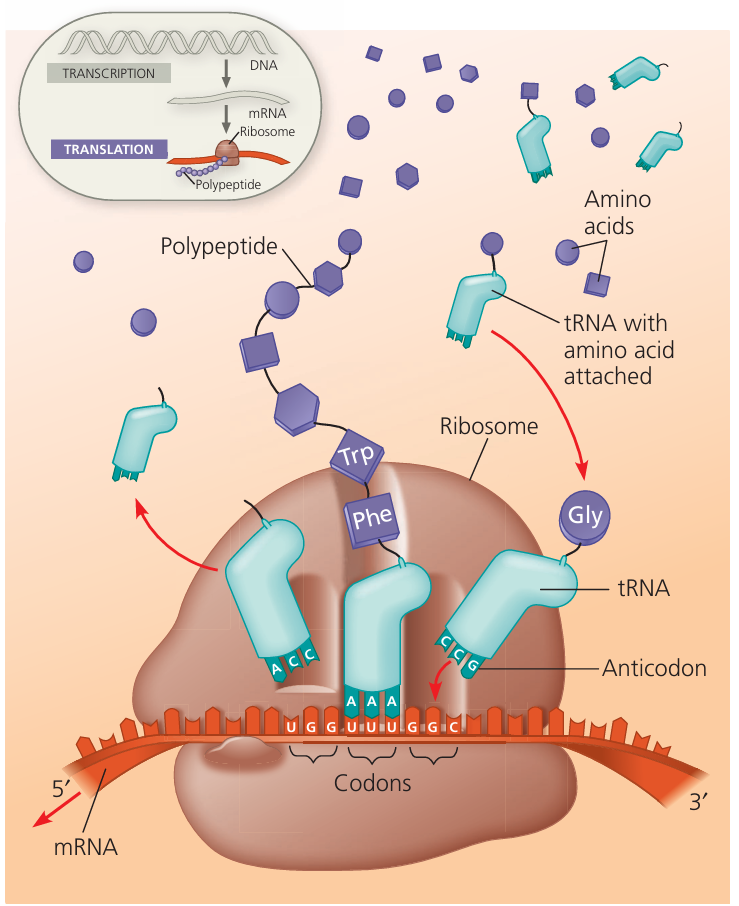
Translation is the process of building a polypeptide (protein) by reading the base sequence of mRNA.
The sequence of bases in mRNA determines the order of amino acids in the polypeptide.
🧩 How Does Translation Work?
- The genetic code on mRNA is read in groups of three bases called codons.
- Each codon corresponds to a specific amino acid.
- Amino acids are linked together in the exact order specified by the mRNA sequence to form a polypeptide chain.
🌍 Where Does Translation Occur?
Takes place in the cytoplasm.
- In eukaryotes, mRNA is produced in the nucleus and moves through nuclear pores into the cytoplasm.
- In prokaryotes, transcription and translation happen in the same area because there is no nucleus.
🔑 Role of mRNA
mRNA (messenger RNA) carries the genetic information copied from DNA.
It acts as a template for assembling amino acids into a polypeptide.
Translation converts the genetic code in mRNA into a specific sequence of amino acids, synthesizing polypeptides that form proteins, a key step in gene expression.
D1.2.8 – Features of the Genetic Code
🔍 Why a Triplet Code?
The genetic code uses 3 bases (a triplet) to code for one amino acid.
This is because:
– There are 4 different bases (A, T/U, C, G).
– If only 1 or 2 bases coded for amino acids, the number of possible amino acids would be too small.
– Triplets allow for 64 (4³) combinations, enough to code for all 20 amino acids plus stop signals.
📚 Important Terms
| Term | Meaning |
|---|---|
| Degeneracy | More than one codon can code for the same amino acid. For example, GGU, GGC, GGA, and GGG all code for glycine. This provides a safeguard against some mutations. |
| Universality | The genetic code is nearly the same in all living organisms, from bacteria to humans. This means that the same codon codes for the same amino acid across species, showing common ancestry. |
⚙️ Key Features of the Genetic Code
- Triplet: 3 bases per codon.
- Non-overlapping: Each base is part of only one codon.
- Degenerate: Multiple codons for many amino acids.
- Universal: The code is consistent across almost all organisms.
- Start and Stop signals: Specific codons signal the start (AUG) and stop of translation.
The triplet genetic code provides enough combinations to specify all amino acids. Its degeneracy offers protection from mutations, and its universality reflects the shared biology of life.
D1.2.11 – Mutations That Change Protein Structure
🔍 What is a Mutation?
A mutation is a change in the DNA base sequence.
This change can alter the sequence of amino acids in a protein, potentially changing its structure and function.
🧩 Types of Mutations Affecting Protein Structure
Point mutations: Changes to a single base in the DNA sequence.
These mutations can lead to:
- Missense mutation: One amino acid is swapped for another.
- Nonsense mutation: A stop codon is introduced prematurely, truncating the protein.
- Silent mutation: No change to the amino acid (due to degeneracy of the code).
📌 Example: Sickle Cell Anemia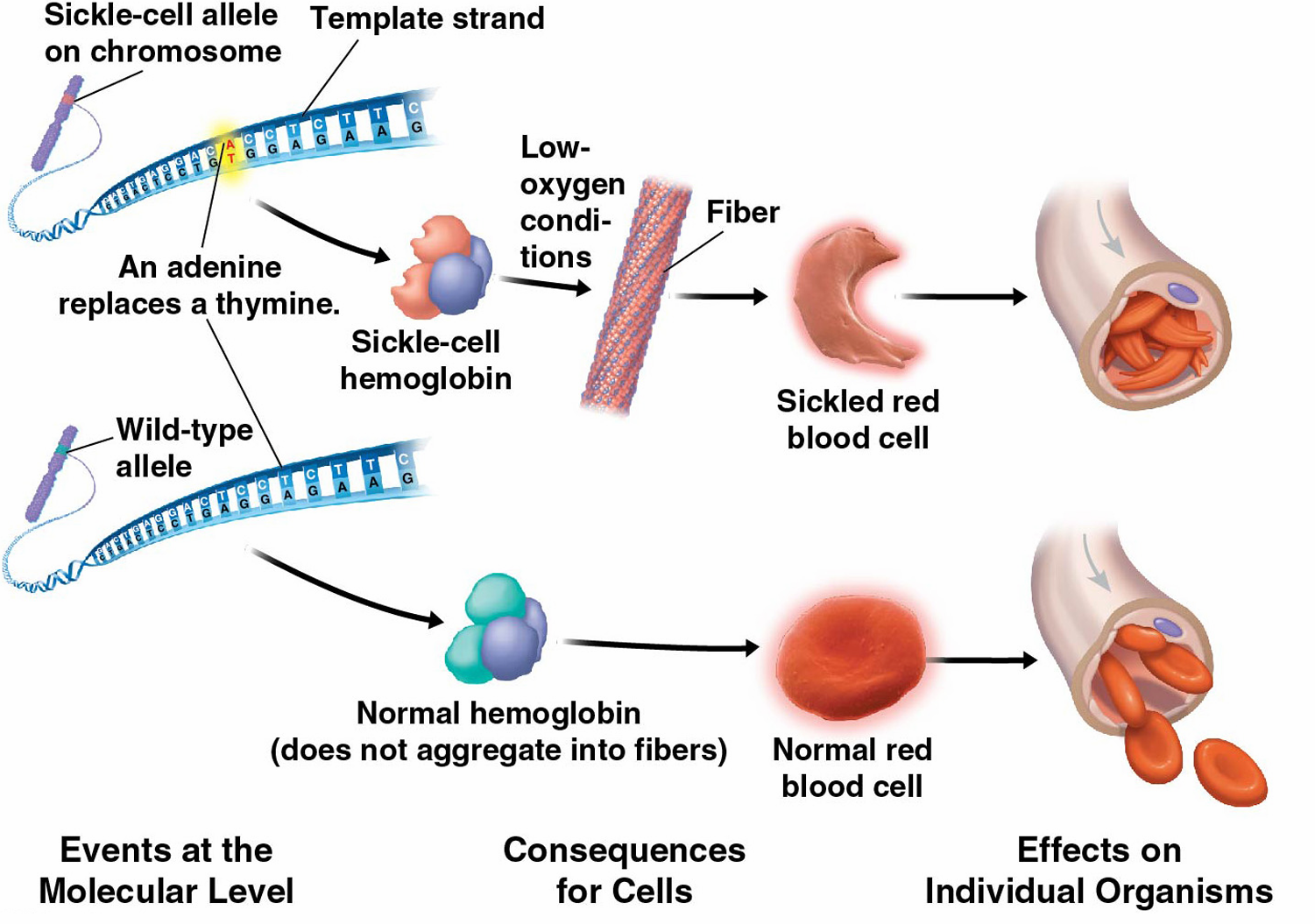
Point mutation in the gene for hemoglobin:
DNA change: A single base substitution (adenine replaced by thymine).
Protein effect: Glutamic acid is replaced by valine at position 6 in the β-globin chain.
This causes hemoglobin molecules to stick together, changing red blood cells into a sickle shape.
Consequences:
Reduced oxygen transport.
Blocked blood vessels, causing pain and tissue damage.
⚠️ Why Mutations Matter
- Even a single base change can drastically alter protein shape and function.
- Some mutations may be harmful, neutral, or rarely beneficial.
- Mutations contribute to genetic diversity but can also cause diseases.
Point mutations alter protein structure by changing amino acids; for example, sickle cell anemia results from a single amino acid substitution in hemoglobin.
D1.2.13 – Initiation of Transcription at the Promoter
🔑 What is the Promoter?
The promoter is a specific DNA sequence located just before (upstream of) the gene to be transcribed.
It acts like a start signal for transcription.
🛠️ How Does Transcription Start?
- Special proteins called transcription factors bind to the promoter region.
- These factors help RNA polymerase attach to the DNA at the promoter.
- Once RNA polymerase is correctly positioned, it begins to unwind the DNA and starts synthesizing RNA.
⚙️ Key Points
- The promoter controls when and where a gene is transcribed.
- Transcription factors regulate gene expression by controlling RNA polymerase binding.
- Students don’t need to memorize the names of specific transcription factors, just their role.
Transcription starts at the promoter where transcription factors bind, enabling RNA polymerase to attach and begin making RNA from DNA.
D1.2.15 – Post-Transcriptional Modification in Eukaryotic Cells
🧬 What Is Post-Transcriptional Modification (PTM)?
PTM is the process where the initial RNA transcript (pre-mRNA) is chemically altered to form mature mRNA.
This is essential because only mature mRNA can be correctly translated into proteins in eukaryotic cells.
PTM increases stability and functionality of the mRNA.
🌿 Main Steps of Post-Transcriptional Modification
| Step | Process | Purpose |
|---|---|---|
| 1. Capping | Addition of a methylated guanine cap to the 5′ end of mRNA | Protects mRNA from degradation and helps ribosomes recognize the mRNA for translation |
| 2. Polyadenylation | Addition of a poly-A tail (many adenine nucleotides) to the 3′ end | Stabilizes mRNA and helps its export from nucleus to cytoplasm |
| 3. Splicing | Removal of introns (non-coding sequences) and joining of exons (coding sequences) | Produces a continuous coding sequence for protein synthesis |
🔬 Why Splicing Is Important
- Eukaryotic genes contain introns and exons.
- Introns do not code for proteins and must be removed.
- Splicing creates an accurate, continuous coding sequence.
- This process is carried out by a complex called the spliceosome.
📌 Other Types of Post-Transcriptional Modifications
| Modification | Description | Biological Role |
|---|---|---|
| N6-methyladenosine (m6A) | Most common PTM; methylation of adenosine bases in RNA | Regulates RNA stability, translation, and involved in diseases like cancer |
| Cleavage | Cutting RNA at specific sites | Helps process some RNAs for function |
| Thiolation | Addition of sulfur-containing groups | Affects RNA stability/function |
| Isopentenylation | Attachment of isopentenyl groups | Modifies RNA activity |
| Pseudouridine formation | Conversion of uridine to pseudouridine | Influences RNA folding and stability |
🌱 Dynamic and Reversible
PTM is not permanent.
Cells can reverse modifications to rapidly respond to environmental or developmental changes.
PTM transforms pre-mRNA into mature mRNA by adding a 5′ cap, a 3′ poly-A tail, and removing introns.
This process is essential for mRNA stability, nuclear export, and translation.
Other PTMs fine-tune RNA function and are important in gene regulation and health.
PTM is dynamic, allowing flexibility in gene expression.
D1.2.17 – Initiation of Translation
🧬 What Is Initiation of Translation?
The first step in making proteins where the ribosome assembles on the mRNA and gets ready to build the polypeptide chain.
Happens in the cytoplasm of eukaryotic cells.
🌿 Steps of Initiation
- Small ribosomal subunit (40S in eukaryotes) attaches to the 5′ end of the mRNA.
- It scans along the mRNA to find the start codon (AUG).
- The initiator tRNA carrying methionine pairs its anticodon with the start codon at the P site of the ribosome.
- The large ribosomal subunit (60S) joins to form the complete 80S ribosome.
- A second tRNA carrying an amino acid bind to the A site, ready to add the next amino acid.
🔬 Roles of Ribosome Binding Sites
| Site | Function |
|---|---|
| A site (Aminoacyl site) | Holds the tRNA with the next amino acid to be added |
| P site (Peptidyl site) | Holds the tRNA carrying the growing polypeptide chain (starts with initiator tRNA) |
| E site (Exit site) | Where empty tRNA leaves the ribosome after its amino acid is added |
📌 Additional Details
- In eukaryotes, initiation factors like eIF1 and eIF1A help the small subunit recognize the start codon and position the initiator tRNA correctly.
- The process requires energy from GTP to assemble the ribosome and place tRNAs.
- The small subunit scans from the 5′ cap of mRNA to locate the start codon before large subunit binds.
Initiation sets up the ribosome on mRNA with the initiator tRNA at the start codon in the P site.
The small subunit binds first and scans for the start codon.
The large subunit joins to complete the ribosome.
Ribosome has three tRNA sites (A, P, E) crucial for translation elongation.
D1.2.19 – Recycling of Amino Acids by Proteasomes
🧬 What Are Proteasomes?

Proteasomes are protein complexes that break down unwanted or damaged proteins inside cells.
This process is called proteolysis and results in recycling amino acids.
🌿 How Proteasomes Work
- Proteins are marked for destruction by chemical tags added by specific enzymes.
- The proteasome breaks peptide bonds, cutting proteins into amino acids.
- These amino acids are recycled and reused to build new proteins.
📌 Why Is Protein Recycling Important?
- Keeps the cell’s protein content (proteome) functional and balanced.
- Controls protein levels, regulating many cellular processes.
- Prevents accumulation of damaged or faulty proteins.
Maintaining a functional proteome requires constant protein breakdown and synthesis.
Proteasomes play a vital role by recycling amino acids from degraded proteins for reuse.