Quartiles of Discrete Data
Quartiles divide ordered data into four equal parts:
- Q1 (Lower quartile): 25% of the data is below Q1.
- Q2 (Median): 50% of the data is below Q2.
- Q3 (Upper quartile): 75% of the data is below Q3.
Steps to calculate quartiles:
- Order the data from smallest to largest.
- Find Q2 (the median).
- Find Q1 as the median of the lower half (not including Q2 if odd number of data).
- Find Q3 as the median of the upper half (not including Q2 if odd number of data).
Example
Find the quartiles of the data set:
3, 7, 8, 5, 12, 14, 21, 13, 18
▶️Answer/Explanation
- Order the data:
3, 5, 7, 8, 12, 13, 14, 18, 21 - Q2 (Median):
The 5th value: 12 - Q1 (Median of lower half: 3, 5, 7, 8):
Average of 5 and 7: \( \frac{5 + 7}{2} = 6 \) - Q3 (Median of upper half: 13, 14, 18, 21):
Average of 14 and 18: \( \frac{14 + 18}{2} = 16 \)
Quartiles: Q1 = 6, Q2 = 12, Q3 = 16
Example
Suppose 100 students took an exam with scores between 1 and 60. The grouped frequency table is:

Determine the quartiles, draw a box plot, and identify any outliers.
▶️ Answer/Explanation
Use cumulative frequency diagram.

- \( Q_1 \): 25th percentile ≈ 25
- \( Q_2 \): 50th percentile (Median) ≈ 38
- \( Q_3 \): 75th percentile ≈ 46
Draw Box and Whisker Plot
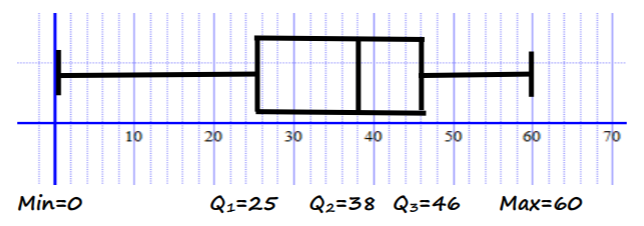
Calculate IQR and check for outliers
$ \text{IQR} = Q_3 – Q_1 = 46 – 25 = 21 $
$ \text{Lower boundary} = Q_1 – 1.5 \times \text{IQR} = 25 – 1.5 \times 21 = -6.5 $
$ \text{Upper boundary} = Q_3 + 1.5 \times \text{IQR} = 46 + 1.5 \times 21 = 77.5 $
Conclusion: No outliers exist in the data set.