Non-linear regression models describe relationships between variables that cannot be captured with a straight line. These models are especially useful in AI and data science where real-world data often exhibits non-linear behavior.
Types of Non-Linear Regression Models
Quadratic Regression
Formula: $y = ax^2 + bx + c$

Used when data forms a parabolic curve, such as in projectile motion.
Cubic Regression
Formula: $y = ax^3 + bx^2 + cx + d$
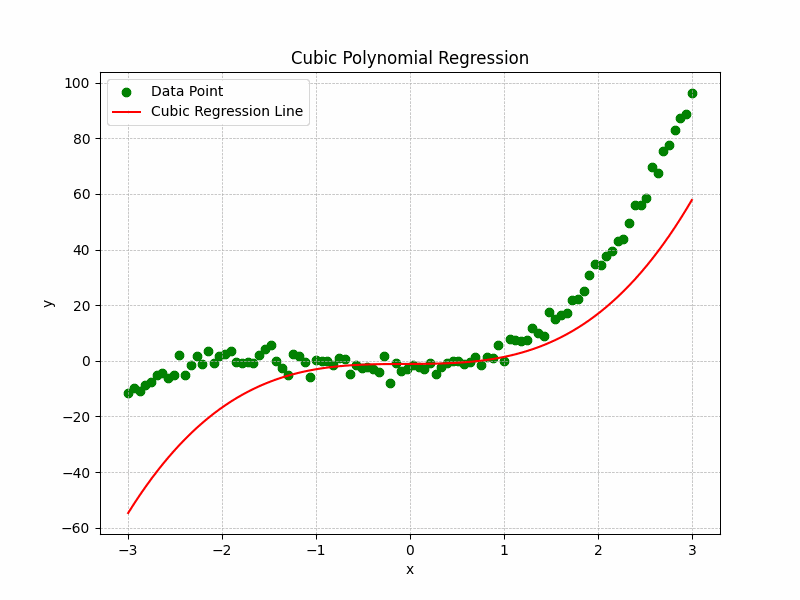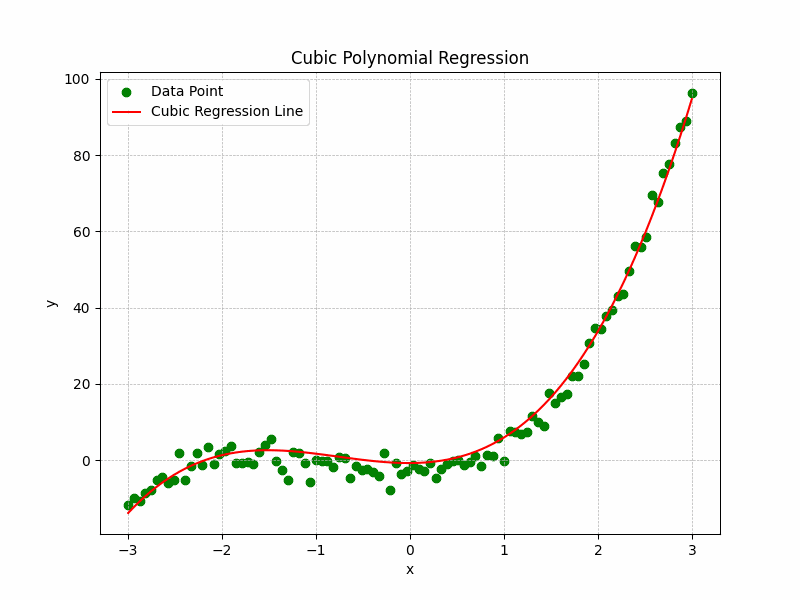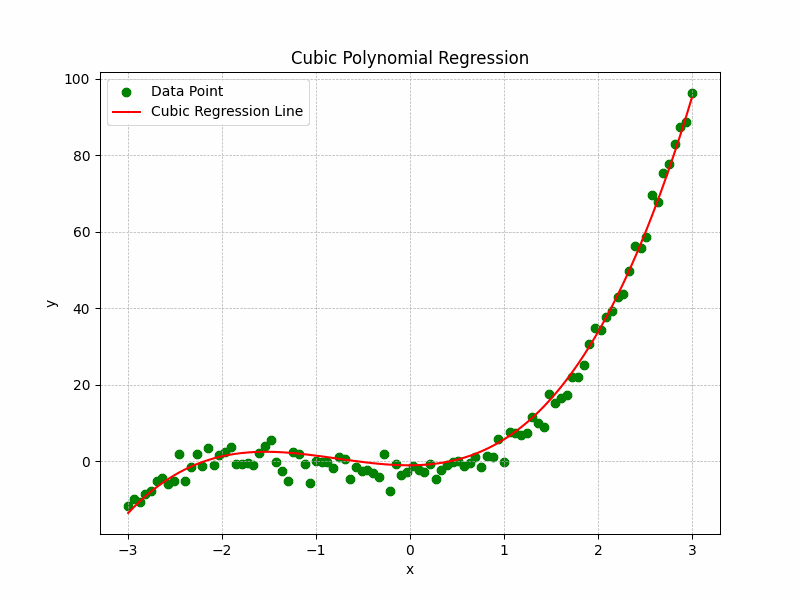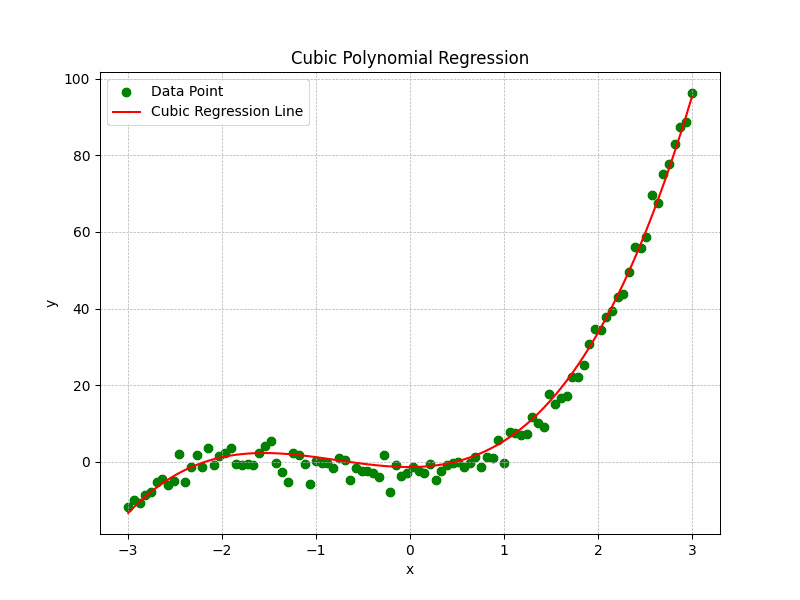
Useful when data has more than one curve or inflection point.
Exponential Regression
Formula: $y = ab^x$ or $y = ae^{bx}$
Appropriate for growth or decay processes, such as population growth or bacterial growth.
Power Regression
Formula: $y = ax^b$
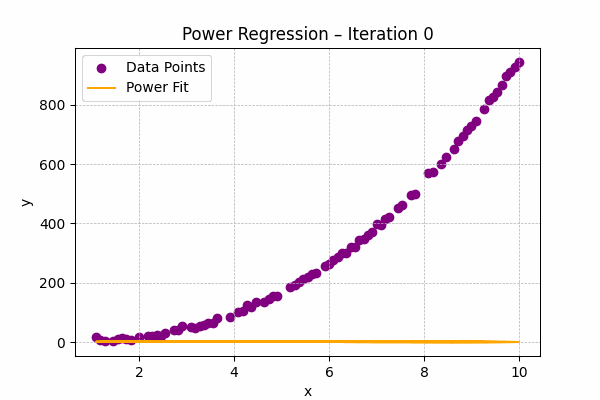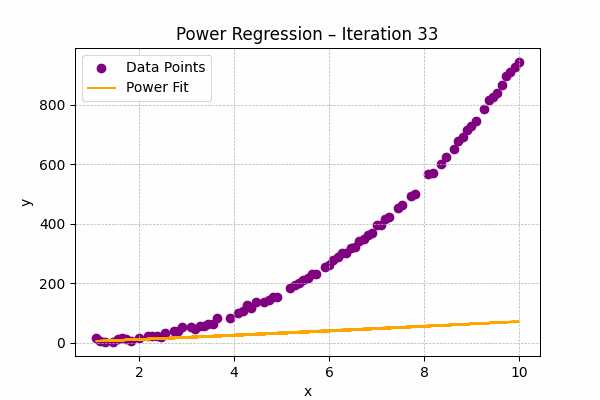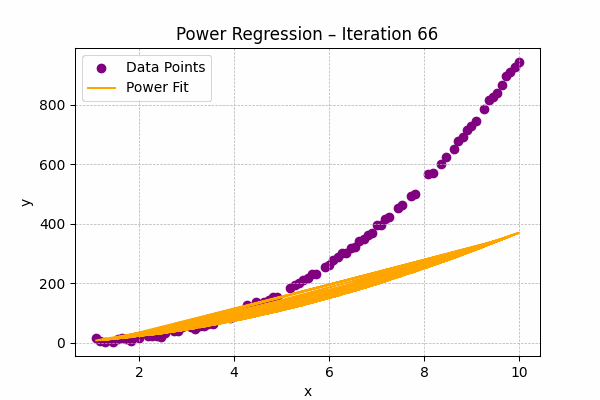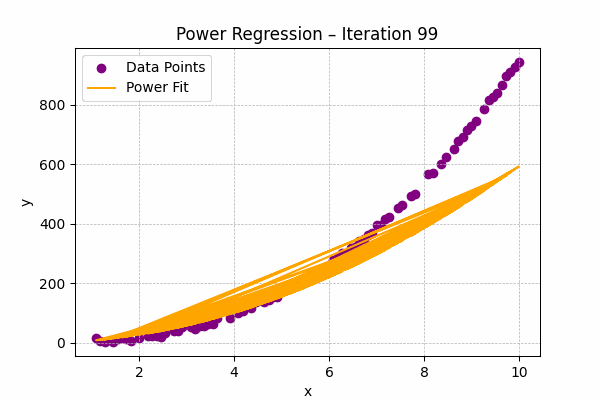
Used when one variable changes at a rate proportional to a power of another, often found in physics or engineering.
Sine Regression
Formula: $y = a\sin(bx + c) + d$
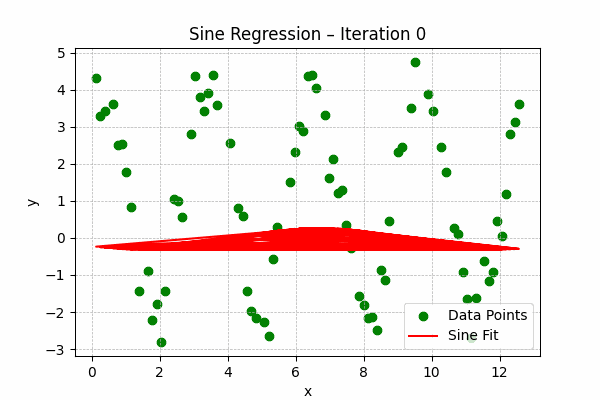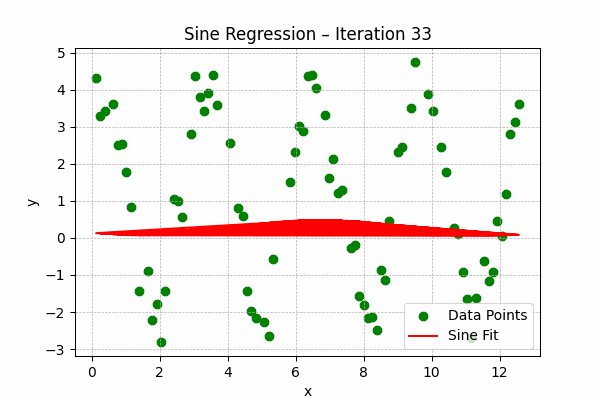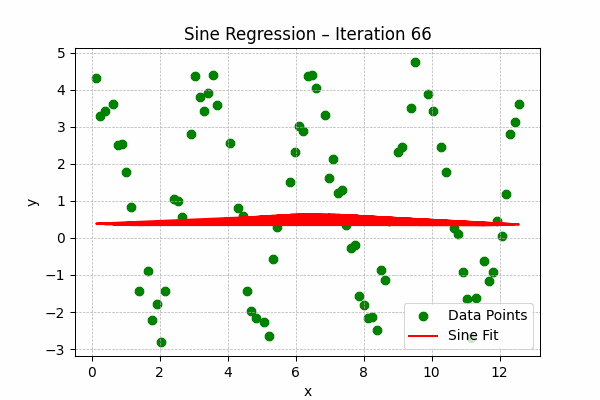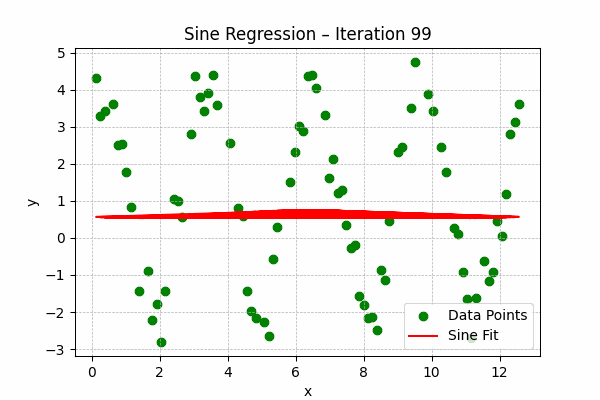
Best for periodic or oscillatory data, such as seasonal trends or sound waves.
Example Applications
Exponential Model: Predicting population growth.
Sine Model: Modeling temperature cycles or light intensity.
Selecting the Appropriate Model
The choice of model depends on data patterns:
- Quadratic: One curve, either concave up or down.
- Cubic: Multiple bends or inflection points.
- Exponential: Rapid growth or decay.
- Power: Steady increase/decrease at a variable rate.
- Sine: Repetitive, periodic trends.
Least Squares Method – Linear Regression
The least squares method is used to find the line of best fit (regression line) for a set of data. This line minimizes the sum of the squares of the vertical distances (errors) between the observed values and the values predicted by the line.
Line of best fit: \( y = mx + c \)
Formulas:
- Slope: \( m = \dfrac{n\sum xy – \sum x \sum y}{n\sum x^2 – (\sum x)^2} \)
- Intercept: \( c = \dfrac{\sum y – m\sum x}{n} \)
Example
Given the following data, find the least squares regression line:
| x | y |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 5 |
| 4 | 4 |
| 5 | 6 |
▶️ Answer/Explanation
\[ \sum x = 1+2+3+4+5 = 15,\quad \sum y = 2+3+5+4+6 = 20 \]
\[ \sum x^2 = 1^2 + 2^2 + 3^2 + 4^2 + 5^2 = 55,\quad \sum xy = (1)(2) + (2)(3) + (3)(5) + (4)(4) + (5)(6) = 69 \]
Number of data points: \( n = 5 \)
The least squares regression line is: \[ \boxed{y = 0.9x + 1.3} \]
In the Context of AI
In AI and machine learning, regression techniques help model relationships and make predictions. Non-linear regression is essential for capturing complex patterns that linear models miss.
Exam Tip
Use graphing calculators or software like Desmos or Excel to fit different regression models and assess which best suits the data. Visual pattern recognition is key.