Topic 2.7: dna replication, transcription and translation
In the DNA Replication, Transcription and Translation unit you will learn the details of how and why DNA Replicates. You will also learn how the DNA codes for specific amino acids and how this information is transcribed from the DNA to make proteins.
The unit is planned to take 3 school days.
Essential Idea:
- Genetic information in DNA can be accurately copied and can be translated to make the proteins needed by the cell.
Nature of science:
- Obtaining evidence for scientific theories—Meselson and Stahl obtained evidence for the semi-conservative replication of DNA. (1.8)
- Describe the procedure of the Meselson and Stahl experiment.
- Explain how the Meselson and Stahl experiment demonstrated semi-conservative DNA replication
2.7.U1 The replication of DNA is semi-conservative and depends on complementary base pairing.
- Describe the meaning of “semiconservative” in relation to DNA replication.
- Explain the role of complementary base pairing in DNA replication.
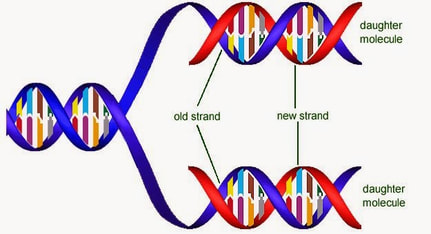
DNA replication is a semi-conservative process, because when a new double-stranded DNA molecule is formed:
- One strand will be from the original template molecule
- One strand will be newly synthesisd
- When a cell is preparing to divide, the two strands of the double helix separate. The new strands are used as a guide or template for the creation of a new strand.
- New strands are formed by adding nucleotides, one by one, and linking them together
- The results of this process is 2 DNA molecules, both made up of the original strand and a newly synthesized strand.
- Therefore DNA replication is referred to as being semi-conservative.
The base sequence on the template strand determines the base sequence on the new strand, only a nucleotide carrying a base that is complementary to the next base on the template strand can successfully be added to the new strand.
Since complementary bases form hydrogen bonds with each, stabilizing the structure, if a nucleotide with the wrong base started to be inserted, the hydrogen bond would not happen and the nucleotide would not be added to the chain
Rule – one base always pairs with another is called complementary base pairing.This makes sure that the two DNA molecules that are created by DNA replication are identical in their base sequences to the parent molecule that was replicated.
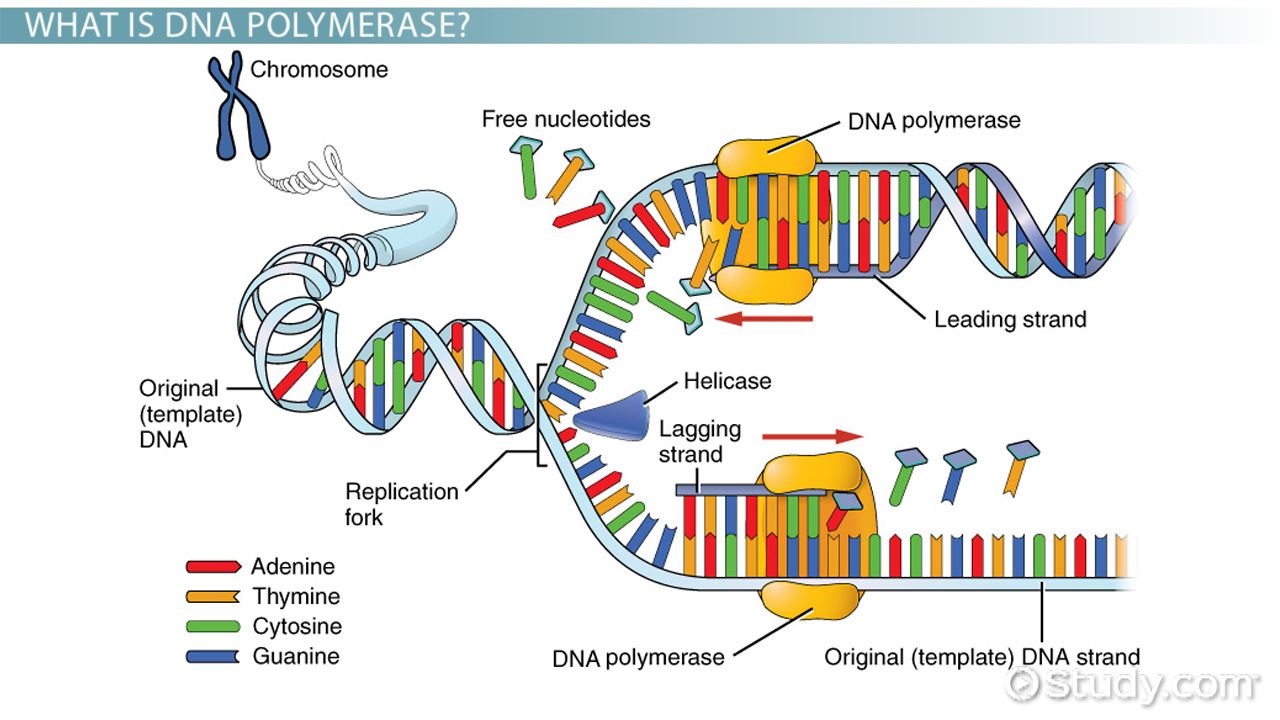
2.7.U2 Helicase unwinds the double helix and separates the two strands by breaking hydrogen bonds.
- State why DNA strands must be separated prior to replication.
- Outline two functions of helicase.
- State the role of the origin of replication in DNA replication.
- Contrast the number of origins in prokaryotic cells to the number in eukaryotic cells.
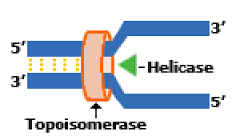
DNA replication is a semi-conservative process whereby pre-existing strands act as templates for newly synthesised strands. The process of DNA replication is coordinated by two key enzymes – helicase and DNA polymerase. To separate the two strands of molecules, this separation is carried out by helicases
- Helixcases is a group of enzymes that use energy from ATP, the energy is required for breaking hydrogen bonds between complementary bases
- Contains six golbular polypeptides arranged in a donuts shape, the polypeptides assemble with one strand of the DNA molecule passing through the center of the donut and the other outside it.
- Energy from ATP is used to help move the helicase along the DNA molecule breaking the hydrogen bonds between the bases and parting the two strands.
- Double stranded DNA can’t be split into two strands while it is till helical therefore helicase causes unwinding of the helix at the same time as it separates the strand
2.7.U3 DNA polymerase links nucleotides together to form a new strand, using the pre-existing strand as a template.
- Describe the movement of DNA polymerase along the DNA template strand.
- Describe the action of DNA polymerase III in pairing nucleotides during DNA replication.
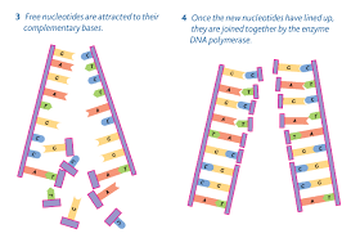
The creation of new strands is carried out by enzyme DNA polymerase
- DNA polymerase move along the template strand in the same direction, adding one nucleotide at a time
- Free nucleotides with each of the four possible bases are available in the area where DNA is being replicated
- Every time a nucleotide is added to the new strand only one of the four types of nucleotide has the base that can pair with the base at the position reached on the template strand.
- DNA polymerase brings nucleotides into the position where hydrogen bonds could be formed but unless this happens and a complementary base pair is formed, the nucleotide break away again
- Nucleotide is finally as the correct base and has been brought into position and hydrogen bonds have been formed between the two bases, DNA polymerase links it to the end of the new strand
- This is done with Covalent bonds between the phosphate group of the free nucleotide and the sugar of the nucleotide at the existing end of the new strand
- Pentose sugar is 3 terminal and the phosphate is the 5 terminal, DNA polymerase adds on the 5 terminal of the free nucleotide to the 3 terminal of the existing
- DNA polymerase continues to move along the template strand creating new strands with a base sequence complementary to the template strand – it does this with a very high degree of fidelity (very few mistakes made)
2.7.U4 Transcription is the synthesis of mRNA copied from the DNA base sequences by RNA polymerase.
- Define transcription.
- Outline the process of transcription, including the role of RNA polymerase and complementary base pairing.
- Identify the sense and antisense strands of DNA given a diagram of translation.
Transcription is the synthesis of mRNA copied from the DNA base sequences by RNA polymerase. Sequence of bases in a gene does not, in itself, give any observable characteristic in an organism. Function of most genes is to specify the sequence of amino acids in a particular polypeptide – it is proteins that are often directly or indirectly determine the observable characteristics of an individual. Two processes are needed to produce a specific polypeptide, using the base sequence of a gene
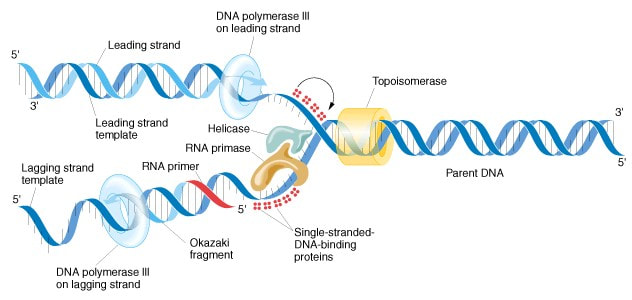
Transcription – the synthesis of RNA, using DNA as a template, because RNA is a single-stranded, transcription only occurs along one of the two strands of DNA
- The enzyme RNA polymerase binds to a site on the DNA at the start of the gene
- RNA polymerase moves along the gene separating DNA into single strands and pairing up RNA nucleotides with complementary bases on one strand of the DNA – [no thymine in RNA so uracil pairs in a complementary fashion with adenine]
- RNA polymerase forms covalent bonds between the RNA nucleotides
- RNA separates from the DNA and the double heliz reforms
- Transcription stops at the end of the gene and the completed RNA molecule is release
- Product of transcription is molecule of RNA with a base sequence that is complementary to the template strand of DNA
- RNA has a base sequence that is identical to the other strand with one exception there is uracil in place of thymine- to make an RNA copy of the base sequence of one strand of a DNA molecule, the other strand is transcribed.
- DNA with the same base sequence as the RNA is called the SENSE STRAND
- other strand that acts as the template and has a complementary base sequence to both the RNA and the sense strand is called the antisense strand
2.7.U5 Translation is the synthesis of polypeptides on ribosomes.
- Define translation.
- State the location of translation in the cell.
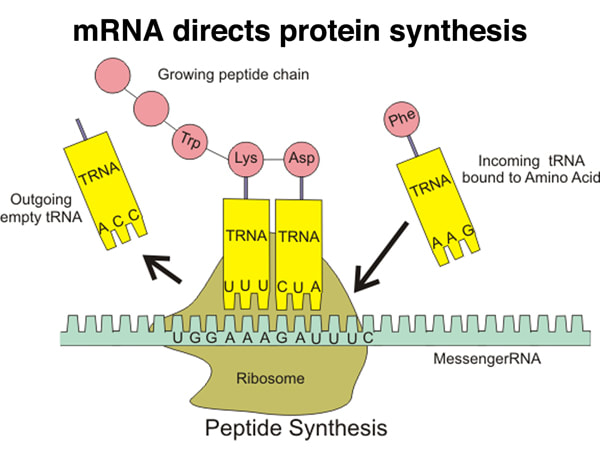
Translation is synthesis of polypeptides on ribosomes. This is the second of the two processes needed to produce a specific polypeptide
- Synthesis of polypeptide with an amino acid sequence chosen by the base sequence of a molecule of RNA
- It takes place on the cell structure in the cytoplasm known as ribosomes – they are complex structures that consist of a small and a large subunit, with binding sites for each of the molecules that take place in the translation-
Messenger RNA and the genetic code
- The amino acid sequence of polypeptides is determined by mRNA according to the genetic code
- RNA that carries information needed to synthesize a polypeptide is called mRNA
- Length of mRNA depends on the amount of amino acids in the polypeptide
- Genome – many different genes that carry the information needed to make polypeptide with a specific amino acid sequence
- Certain genes are transcribed when anytime a cell will only need to make some of these polypeptides/ only some will be available for the translation in the cytoplasm
Translation Mnemonic
The key components of translation are:
- Messenger RNA (goes to…)
- Ribosome (reads sequence in …)
- Codons (recognised by …)
- Anticodons (found on …)
- Transfer RNA (which carries …)
- Amino acids (which join via …)
- Peptide bonds (to form …)
- Polypeptides
Mnemonic: Mr Cat App
2.7.U6 The amino acid sequence of polypeptides is determined by mRNA according to the genetic code.
- Outline the role of messenger RNA in translation.
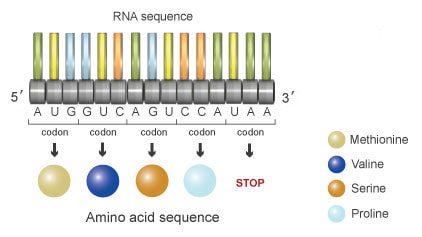
Condons help the cellular machinery to convert the base sequence on the mRNA into an amino acid sequence is called the genetic code.
- Four different bases and 20 amino acids – so one base can’t code for one amino acids
- 16 combos for 2 bases = still too few therefore living organisms use a triplet code
- Sequence of three bases is called codon – each codon codes for a specific amino acid to be added to the polypeptide
- Amino acids are carried on another kind of RNA called tRNA, each has a specific ( has three base anticondon complementary to the mRNA codon for the particular amino acid
The genetic code is the set of rules by which information encoded within mRNA sequences is converted into amino acid sequences (polypeptides) by living cells. The genetic code identifies the corresponding amino acid for each codon combination. As there are four possible bases in a nucleotide sequence, and three bases per codon, there are 64 codon possibilities (43). The coding region of an mRNA sequence always begins with a START codon (AUG) and terminates with a STOP codon
2.7.U7 Codons of three bases on mRNA correspond to one amino acid in a polypeptide.
- Define codon, redundant and degenerate as related to the genetic code.
- Explain how using a 4 letters nucleic acid “language” can code for a “language” of 20 amino acid letters in proteins.
The base sequence in a DNA molecule, represented by the letters A T C G, make up the genetic code. The bases hydrogen bond together in a complementary manner between strands. A will always go with T (U in RNA) and G will always go with C.
This code determines the type of amino acids and the order in which they are joined together to make a specific protein. The sequence of amino acids in a protein determines its structure and function. The DNA code is a triplet code. Each triplet, a group of three bases, codes for a specific amino acid:
- the triplet of bases on the DNA and mRNA is known as a codon
- the triplet of bases on the tRNA is known as an anti-codon
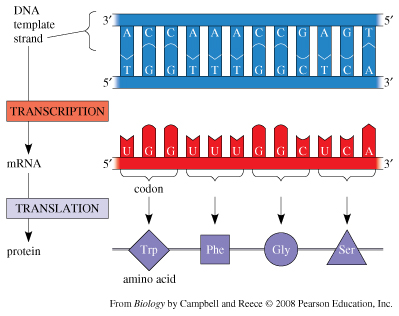
2.7.U8 Translation depends on complementary base pairing between codons on mRNA and anticodons on tRNA.
- Outline the role of complementary base pairing between mRNA and tRNA in translation.
Translation is the process of protein synthesis in which the genetic information encoded in mRNA is translated into a sequence of amino acids on a polypeptide chain
- Ribosomes bind to mRNA in the cytoplasm and move along the molecule in a 5’ – 3’ direction until it reaches a start codon (AUG)
- Anticodons on tRNA molecules align opposite appropriate codons according to complementary base pairing (e.g. AUG = UAC)
- Each tRNA molecule carries a specific amino acid (according to the genetic code)
- Ribosomes catalyse the formation of peptide bonds between adjacent amino acids (via condensation reactions)
- The ribosome moves along the mRNA molecule synthesising a polypeptide chain until it reaches a stop codon
- At this point translation ceases and the polypeptide chain is released
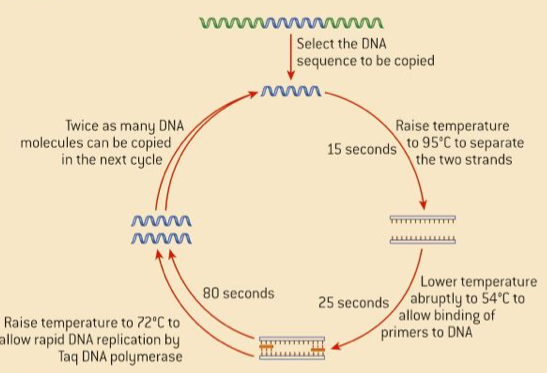
2.7.A1 Use of Taq DNA polymerase to produce multiple copies of DNA rapidly by the polymerase chain reaction (PCR).
- Outline the process of the PCR.
- Explain the use of Taq DNA polymerase in the PCR.
Each reaction doubles the amount of DNA – a standard PCR sequence of 30 cycles creates over 1 billion copies (230). The reaction occurs in a thermal cycler and uses variations in temperature to control the replication process via three steps:
- Denaturation – DNA sample is heated (~90ºC) to separate the two strands
- Annealing – Sample is cooled (~55ºC) to allow primers to anneal (primers designate sequence to be copied)
- Elongation – Sample is heated to the optimal temperature for a heat-tolerant polymerase (Taq) to function (~75ºC)
- Repeatedly doubles the quantity of the selected DNA, involves double-stranded DNA being separated into two single strands at one stage of the cycle and single strands combining to form double-stranded DNA at another stage.
- Reannealing – DNA is heated to a high temperature causing hydrogen bonds to break and the two strands separate. DNA is then cooled hydrogen bonds can form, so the strands pair up again
- PCR machine separates DNA strands by heating them to 95 C for 15 seconds then cooling the DNA quickly to 54 C
- This process allows the reannealing of parent strands to form double-stranded DNA
- A large amount of short sections of single-stranded DNA called primers is present. These primers bind rapidly to target sequences and as a large excess of primers is present, they prevent the re-annealing of the parent strands – causing the copying of the single parent strands then starts from the primers
- Next stage – is synthesis of double stranded DNA,using the single strands with primers as templates – enzyme Taq DNA polymerase is used to do this
- It was taken from a bacterium, Thermus aquaticus, the DNA polymerase are very adapted to be very heat-stable to resist denaturation
- Taq DNA polymerase is used because it can resist the brief period at 95 C used to separate the DNA
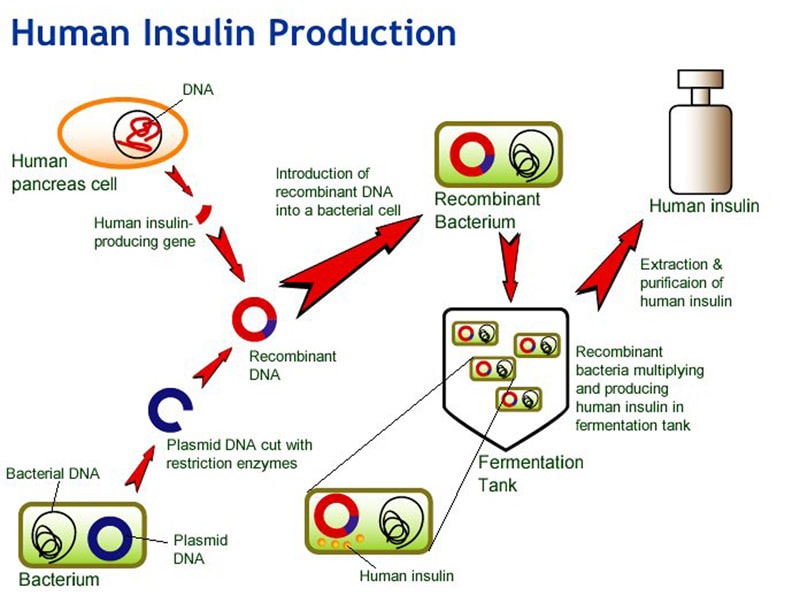
2.7.A2 Production of human insulin in bacteria as an example of the universality of the genetic code allowing gene transfer between species.
- Outline the source and use of pharmaceutical insulin prior to the use of gene transfer technology.
- Outline the benefits of using gene transfer technology in the production of pharmaceutical insulin.
The set of DNA and RNA sequences that determine the amino acid sequences used in the synthesis of an organism’s proteins. It is the biochemical basis of heredity and nearly universal in all organisms. The same genetic code appears to operate in all living things, but exceptions to this universality are known.
Since the same codons code for the same amino acids in all living things, genetic information is transferrable between species. The ability to transfer genes between species has been utilised to produce human insulin in bacteria (for mass production)
- The gene responsible for insulin production is extracted from a human cell
- It is spliced into a plasmid vector (for autonomous replication and expression) before being inserted into a bacterial cell
- The transgenic bacteria (typically E. coli) are then selected and cultured in a fermentation tank (to increase bacterial numbers)
- The bacteria now produce human insulin, which is harvested, purified and packaged for human use (i.e. by diabetics)
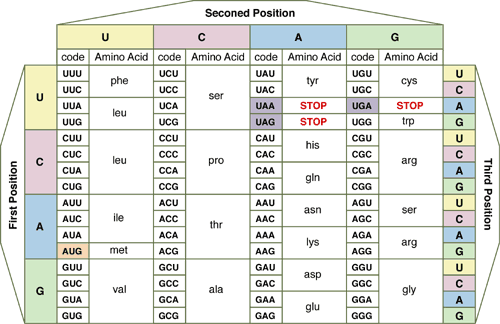
2.7.S1 Use a table of the genetic code to deduce which codon(s) corresponds to which amino acid.
- Use a genetic code table to deduce the mRNA codon(s) given the name of an amino acid.
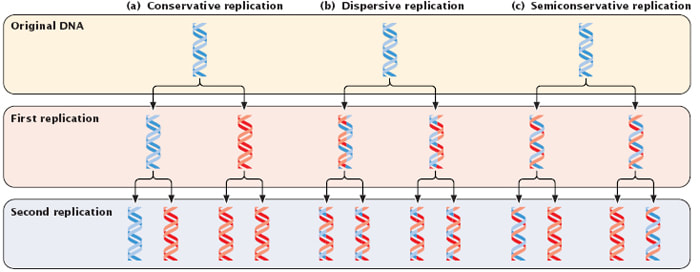
2.7.S2 Analysis of Meselson and Stahl’s results to obtain support for the theory of semi-conservative replication of DNA.
- Compare dispersive, conservative and semi-conservative replication.
- Predict experimental results in the Meselson and Stahl experiment if DNA replication was dispersive, conservative or semi-conservative.
The theory that DNA replication was semi-conservative was confirmed by the Meselson-Stahl experiment in 1958
Prior to this experiment, three hypotheses had been proposed for the method of replication of DNA:
- Conservative Model – An entirely new molecule is synthesised from a DNA template (which remains unaltered)
- Semi-Conservative Model – Each new molecule consists of one newly synthesised strand and one template strand
- Dispersive Model – New molecules are made of segments of new and old DNA
S 2.7.3 Use a table of mRNA codons and their corresponding amino acids to deduce the sequence of amino acids coded by a short mRNA strand of known base sequence.
- Use a genetic code table to determine the amino acid sequence coded for by a given antisense DNA sequence or an mRNA sequence.
In order to translate an mRNA sequence into a polypeptide chain, it is important to establish the correct sequence The mRNA transcript is organised into triplets of bases called codons, and as such three different reading sequences exists
An open sequence will always start with AUG and will continue in triplets to a termination codon. A blocked sequence may be interrupted by termination codons. Once the start codon (AUG) has been located and sequence established, the corresponding amino acid sequence can be determined by using the genetic code
2.7.S4 Deducing the DNA base sequence for the mRNA strand.
- Deduce the antisense DNA base sequence that was transcribed to produce a given mRNA sequence.
mRNA is a complementary copy of a DNA segment (gene) and consequently can be used to deduce the gene sequence. For converting a sequence from mRNA to the original DNA code, apply the rules of complementary base pairing:
- Cytosine (C) is replaced with Guanine (G) – and vice versa
- Uracil (U) is replaced by Adenine (A)
- Adenine (A) is replaced by Thymine (T)